Macros, types and conventions:
long IS_ERR(const
void *ptr) // pointer has value in “error” range (>= (unsigned
long) –MAX_ERRNO)
long IS_ERR_OR_NULL(const
void *ptr)
long PTR_ERR(const
void *ptr)
void* ERR_PTR(long error)
likely(cond)
unlikely(uncond)
BUG_ON(condition)
// can compile away, so do not create side
effects in condition
BUILD_BUG_ON(condition) //
build-time checking
typecheck(__u64,
a) // build-time checking that a is of type __u64
container_of(member_ptr,
container_typename, member_name)
BITS_PER_LONG // 32 or 64
No floating point operations in kernel (there are routines to save/restore fp context).
Interrupt stack (optional. present only on some architectures), normally 1 page (on x86/x64 – 4K).
Kernel stack: on x86/x64
usually 2 pages, i.e. 8 KB.
At the bottom of the stack is struct thread_info.
On stack overflow will silently overwrite it with disastrous consequences.
struct thread_info* current_thread_info();
current_thread_info()->preempt_count
struct task struct* task =
current_thread_info()->task;
struct task struct* task = current;
/* task->state */
TASK_RUNNING 0 // currently running or on runqueue waiting to run
TASK_INTERRUPTIBLE 1 // in interruptible sleep
TASK_UNINTERRUPTIBLE 2 // in non-interruptible sleep
__TASK_STOPPED 4 // stopped due to SIGSTOP, SIGTSTP, SIGTTIN or SIGTTOU
__TASK_TRACED 8 // being traced by debugger etc. via ptrace
/* in task->exit_state */
EXIT_ZOMBIE 16 // process has terminated, lingering around to be reaped by parent
EXIT_DEAD 32 // final state after parent collects status with wait4 or waitpid syscalls
/* in task->state again */
TASK_DEAD 64
TASK_WAKEKILL 128 // wake up on fatal signals
TASK_WAKING 256
#define TASK_KILLABLE (TASK_WAKEKILL | TASK_UNINTERRUPTIBLE)
#define TASK_STOPPED (TASK_WAKEKILL | __TASK_STOPPED)
#define TASK_TRACED (TASK_WAKEKILL | __TASK_TRACED)
#define TASK_NORMAL (TASK_INTERRUPTIBLE | TASK_UNINTERRUPTIBLE)
set_task_state(task, state)
Iterate parent tasks
(note: if parent terminates, task is reparented to member of the group or to init)
for (task = current;
task != &init_task; task = task->parent)
{ ... }
Iterate all tasks in the system (expensive):
for_each_process(task)
{ ... }
task = next_task(task);
task = prev_task(task)
Iterate over children tasks:
struct list_head* list;
list_for_each(list, ¤t->children)
{
task = list_entry(list, struct task_struct, sibling);
}
Annotation for functions that can sleep. This macro will print a stack trace if it is executed in an atomic
context (spinlock, irq-handler, ...):
might_sleep()
Modifiers (annotations):
__init place code into the section discarded after kernel or module init
__read_mostly place data in “read mostly”
section to reduce cache line interference
__write_once same as __read_mostly
__page_aligned_bss align data on page boundary and allocate it from bss-page-aligned section
notrace do not instrument this function for profiling
__irq_entry allocate code in section irqentry-text (only if graph tracer is enabled)
__kprobes allocate code in section kprobes-text (only if CONFIG_KPROBES)
asmlinkage assembler-level call linkage
__lockfunc allocate code in section spinlock-text
__kernel designate as kernel-space address
__user, __iomem, __rcu disable dereference (only used by __CHECKER__, see sparse(1))
__nocast sparse will issue warning if
attempted type-conversion to this var (e.g.
signed int value to unsigned var)
__bitwise sparse will issue
warning if __bitwise variables are mixed with other integers
__safe sparse: not used in the codebase
__force sparse: disable warning (e.g.
when casting int to bitwise)
__le32,
__be32 sparse: little
endian, big endian
__must_hold(x) sparse: the specified lock is held on function entry and exit
__acquires(x) sparse: function acquires the specified lock
__releases(x) sparse: function releases the specified lock
__acquire(x)
__release(x)
__cond_lock(x,c)
Sparse:
git://git.kernel.org/pub/scm/devel/sparse/sparse.git
make
make install
then run kernel make:
make
C=1
# run sparse only on files that need to be recompiled
make
C=2
# run sparse on all files, whether recompiled or not
make C=2 CF="-D__CHECK_ENDIAN__" # pass
optional parameters to sparse
Contexts:
·
process
(e.g. syscall), preemptible context
·
process,
non-preemptible context
· bottom-half (DPC/fork-like, but may be threaded, aka “soft interrupt” – e.g. tasklet)
· primary interrupt handler (irq, aka "top half", aka “hard interrupt”)
· PREEMPT_RT only: secondary (threaded) interrupt handler, per-IRQ thread
There are no IPL/IRQL
levels.
SOFTIRQ is executed with hardware interrupts disabled (but tasklet handler enables interrupts
before entering the tasklet routine).
Bottom-half processing can be triggered by:
· return from hardware interrupt (irq_exit)
· local_bh_enable(), including indirect calls
· ksoftirqd kernel thread (per-CPU, runs at low priority)
·
any code that explicitly calls do_softirq(),
__do_softirq(), call_softirq() or invoke_softirq(),
such as network code
Note again that Linux is NOT "true"
IPL/IRQL-based system, and local_irq_enable() or unlocking a spinlock DO NOT
cause SOFTIRQ processing to happen.
Task switch can be triggered by:
· REI to user-space
· REI to kernel-space if (current->preempt_count == 0 && need_resched())
·
unlocking a lock,
including indirect unlock or any other call to preempt_enable(),
if result is (current->preempt_count == 0 && need_resched())
· explicit voluntary call to schedule(), including yield() and blocking functions
Preemption mask:
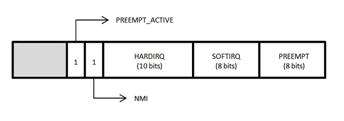
preempt_count()
≡
current_thread_info()->preempt_count
preempt_count() Returns
preemption disable count, this includes count masks added
by
currently active hardirqs, softirqs and NMI. Low byte is preempt
disable
count (if kernel is configured preemptible, otherwise 0),
byte
1 is softirq count, next 10 bits is hardirq count,
then
1 bit for NMI, then one bit for PREEMPT_ACTIVE.
There is also preempt_lazy_count (useful for PREEMPT_RT)
SOFTIRQ is changed by 1
on entering/leaving softirq processing and is changed by 2 on local_bh_enable/local_bh_disable,
to distinguish between softirq-active and softirq-disabled states
PREEMPT_ACTIVE
rescheduling is being performed (so do not reenter the scheduler)
Context control functions:
preempt_disable() increments PREEMPT field
preempt_enable() decrement PREEMT, if goes to 0, will check
for need_reschdule()
local_bh_disable() increments SOFTIRQ field by 2 (whereas entering
softirq increments it
only by 1, to distinguish between
softirq-active/softirq-disabled states)
local_bh_enable() If goes to 0, will check for pending bottom halves (softirqs)
local_irq_disable() disable hw interrupts unconditionally (on
some arch can be lazy)
local_irq_enable() enable hw interrupts unconditionally
unsigned long flags;
local_irq_save(flags) save previous state
into flags and disable hw interrupts
local_irq_restore(flags)
restore hw-interrupt-enable state from flags
Other functions:
hard_irq_disable() Really disable interrupts, rather than
relying on lazy-disabling on
some architectures.
preempt_enable_no_resched() Decrement preemption count. If goes to
0, do not check for any
pending reschedules.
in_nmi() Non-zero if executing NMI handler.
in_irq() Non-zero if currently executing primary (hardirq) hardware
interrupt handler, 0 if in process context or bottom half or NMI.
in_softirq() Non-zero if processing softirq or have BH disabled.
in_servng_softirq() Non-zero if processing softirq.
in_interrupt() Non-zero if in NMI or primary interrupt
(hardirq) or in bottom-half context, or if have BH disabled.
irqs_disabled() Non-zero
if local interrupt delivery is disabled.
in_atomic() Checks (preempt_count() & ~PREEMPT_ACTIVE), cannot sense if
spinlocks are held in
non-preemptable kernel, so use only with
great caution. Do not use in drivers.
synchronize_hardirq(irq) Wait for pending hard IRQ handlers
to complete on other CPUs
synchronize_irq(irq) Wait for pending hard & threaded IRQ
handlers to complete on other CPUs
Warning: on non-preemptible systems
(CONFIG_PREEMPT=n) spin_lock does not
change preemption mask.
Bottom halves:
top half = primary interrupt context
bottom half = deferred interrupt processing (similar to DPC or fork), can be threaded
Methods:
|
original BH |
removed in 2.5 |
|
Task queues |
removed in 2.5 |
|
Softirq |
since 2.3 |
|
Tasklet |
since 2.3 |
|
Work queues |
since 2.3 |
|
Timers |
|
Original BH (removed in 2.5):
32-bit request mask and 32 lists of requests, each level globally synchronized across all CPUs.
Task queues (removed in 2.5):
Set of queues.
Softirqs (BH):
Set of NR_SOFTIRQS statically defined bottom halves allocated at kernel compile time.
Cannot register extra softirq levels dynamically.
Handler can run on any CPU.
Rarely used directly (tasklets are more common), but tasklets are layered on Softirq.
Defined levels:
|
HI_SOFTIRQ |
0 |
High-priority tasklets |
|
TIMER_SOFTIRQ |
1 |
Timers |
|
NET_TX_SOFTIRQ |
2 |
Send network packets |
|
NET_RX_SOFTIRQ |
3 |
Receive network packets |
|
BLOCK_SOFTIRQ |
4 |
Block devices: done |
|
BLOCK_IOPOLL_SOFTIRQ |
5 |
Block devices: poll |
|
TASKLET_SOFTIRQ |
6 |
Normal priority tasklets |
|
SCHED_SOFTIRQ |
7 |
Scheduler (just inter-CPU balancing, not the same as SOFTINT IPL$_RESCHED) |
|
HRTIMER_SOFTIRQ |
8 |
High-resolution timer |
|
RCU_SOFTIRQ |
9 |
RCU callbacks |
Level to name:
extern char *softirq_to_name[NR_SOFTIRQS];
Register handler:
void my_action(struct softirq_action *);
open_softirq(HRTIMER_SOFTIRQ, my_action);
Handler runs with interrupts enabled and cannot sleep.
Raise softirq:
Marks softirq level as pending.
Temporarily disables interrupts internally.
raise_softirq(NET_TX_SOFTIRQ);
Equivalent to:
unsigned long flags;
local_irq_save(flags);
raise_softirq_irqoff(nr);
local_irq_restore(flags);
If interrupts are already disabled, can do:
raise_softirq_irqoff(NET_TX_SOFTIRQ);
Try to send a softirq to a remote cpu.
If this cannot be done, the work will be queued to the local cpu.
void send_remote_softirq(struct call_single_data* cp, int cpu, int softirq);
Softirq processing logic:
do_softirqd is invoked:
· on return from hardware interrupt (irq_exit)
· local_bh_enable()
· in the ksoftirqd kernel thread (per-CPU, runs at low priority)
·
in any code that explicitly calls do_softirq(),
__do_softirq(), call_softirq() or invoke_softirq(),
such as network code
void do_softirq(void)
{
__u32 pending;
unsigned long flags;
struct softirq_action* h;
if (in_interrupt())
return;
local_irq_save(flags);
pending = local_softirq_pending();
if (pending)
{
... on x86 and some other architectures ...
... switch to per-CPU softirq stack ...
set_softirq_pending(0);
local_irq_enable();
h = softirq_vec;
do
{
if (pending & 1)
h->action(h);
h++;
pending >>= 1;
} while (pending);
}
... recheck if still pending, and if so retry the loop few times ...
... after which wakeup softirqd for execution on a worker thread ...
local_irq_restore(flags);
}
Thus:
· Multiple softirqs (of same or different levels) can concurrently execute on different processors.
·
Single pass on the
same CPU goes from high-priority (0) to low-priority (9) softirqs, but in a
larger scheme of things low-priority softirq can get executed earlier than
high-priority softirq.
(E.g. if another processor picks up lower-priority softirq first, or if
high-priority softirq is added while scan pass is already in progress, or if
tasklets are relegated to the threaded execution, of due to ksoftirqd.)
·
softirq’s are
prioritized for ordering only (and even then are subject to postponing for ksoftirqd thread).
high-priority softirq does not interrupt lower-priority softirq.
"While a (softirq) handler runs, softirqs on the
current processor are disabled.
A softirq never preempts another softirq (on the same CPU).
The only event that can preempt a softirq is an interrupt handler."
Tasklets (BH):
Tasklets
· built on top of softirqs
· can be scheduled only as one instance at a time (and also only on one processor at a time)
· if handler is already running on CPU1 and tasklet gets scheduled again on CPU2, second instance of handler can run (on CPU2) concurrently with the first one (running on CPU1)
· handler runs with all interrupts enabled
· does not have process context (no files etc.)
· cannot sleep
· per-processor queues tasklet_vec (for regular tasklets) and tasklet_hi_vec (for high-priority tasklets)
Rules:
· if tasklet_schedule is called, then tasklet is guaranteed to be executed on some CPU at least once after this
· if tasklet is already scheduled, but its execution is still not started, it will be executed only once
· if tasklet is already running on another CPU (or schedule is called from tasklet itself), it is scheduled again
·
tasklet is strictly serialized with
respect to itself, but not to another tasklets;
for inter-tasklet synchronization, use
spinlocks.
struct tasklet_struct
{
struct tasklet_struct *next;
unsigned long state; // bits: TASKLET_STATE_SCHED (0), TASKLET_STATE_RUN (1)
atomic_t
count; // if non-zero, disabled and cannot run
// otherwise enabled and can run if scheduled
void (*func)(unsigned long);
unsigned long data;
}
#define DECLARE_TASKLET(name, func, data) \
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(0), func, data }
#define DECLARE_TASKLET_DISABLED(name, func, data) \
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(1), func, data }
void tasklet_init(struct tasklet_struct *t, void (*func)(unsigned long), unsigned long data)
int tasklet_trylock(struct tasklet_struct *t) // sets RUN bit on MP, return true if was not set
void tasklet_unlock(struct tasklet_struct *t) // clear RUN bit
void tasklet_unlock_wait(struct tasklet_struct *t) // spin while RUN bit is set
No-op on uniprocessor.
void tasklet_schedule(struct tasklet_struct *t)
void tasklet_hi_schedule(struct tasklet_struct *t)
If SCHED is already set, do nothing.
Otherwise insert into queue and signal softirq.
void tasklet_kill(struct tasklet_struct *t);
Cannot be called from interrupt.
Acquire SCHED bit (i.e. wait till owner clears it, e.g after removing from
queue), spin while RUN bit is set, clear SCHED bit.
|
tasklet state at call to tasklet_kill |
outcome |
|
not queued |
returns fine |
|
queued, disabled |
will lock up |
|
enabled, queued |
removed from queue |
|
enabled, running |
void tasklet_kill_immediate(struct tasklet_struct *t, unsigned int cpu);
Can be called only for CPU in state CPU_DEAD.
Remove tasklet even if it is in SCHED state.
void tasklet_disable_nosync(struct tasklet_struct *t)
Disables tasklet by atomic_inc(t->count) and returns immediately.
void tasklet_disable(struct tasklet_struct *t)
Disables tasklet by atomic_inc(t->count) and calls tasklet_unlock_wait().
void tasklet_enable(struct
tasklet_struct *t)
void tasklet_hi_enable(struct tasklet_struct *t)
Enables tasklet by atomic_dec(t->count).
Tasklet block:
func(data)
disable_count
flags: sched (“scheduled”), run (“currently running”)
Handler logic:
|
tasklet_schedule |
softirq handler |
|
{ sched = 1 queue + softirq } |
clear per-cpu queue
for (each entry) {
if (run) requeue: put back on the queue request softirq } else { run = 1
if (disable_count != 0) run = 0 goto requeue } else { sched = 0 func(data) run = 0 } } } |
Work queues (BH):
· items executed by a worker thread, in process context and can sleep
· default threads are per-CPU event/n, but queue can also have dedicated processing thread or threads
wq = create_workqueue("my_queue");
wq = create_singlethread_workqueue("my_queue");
wq = create_freezable_workqueue("my_queue");
NULL if fails.
create_workqueue creates queue and worker threads, one per CPU, named my_queue/n.
pre-existing queues:
|
system_wq |
Used by schedule[_delayed]_work[_on](). For short items. |
|
system_long_wq |
Similar to system_wq, but for
long items. |
|
system_freezable_wq |
Similar to system_wq, but freezable. |
|
system_unbound_wq |
Workers are not bound to any specific CPU, not concurrency managed, and all queued works are executed immediately as long as max_active limit is not reached and resources are available. |
int keventd_up(void)
Check if system_wq exists (not NULL).
void destroy_workqueue( struct workqueue_struct* wq);
void workqueue_set_max_active(wq, int max_active)
Adjust maximum number of concurrently active works.
Do not call from interrupt context.
struct workqueue_struct* wq;
work_struct work;
void my_func(struct work_struct *pWork);
DECLARE_WORK(work, myfunc); // compile-time initialization
INIT_WORK(&work, myfunc) // run-time initialization
INIT_WORK_ONSTACK(&work, myfunc) // ... same for on-stack work object
PREPARE_WORK(&work, new_myfunc) // change the routine in an already initialized descriptor
bool queue_work(wq, pWork) // queue on current CPU
bool schedule_work(pWork) // same as queue_work on system_wq
Returns TRUE if was queued, FALSE if was already on the queue.
If queue is being drained with drain_queue, will not actually insert in the queue unless called from the context of a "chained work", i.e. work executing on this queue, but will not reflect it in return status.
To pass parameters to work routine, embed struct_work in larger structure.
bool queue_work_on(int cpu, wq, pWork) // queue for processing on specified CPU
bool schedule_work_on(int cpu, pWork) // same as queue_work_on on system_wq
Returns TRUE if was queued, FALSE if was already on the
queue.
Caller must ensure the CPU cannot go away.
If queue is being drained with drain_queue, (see above).
struct delayed_work dwork
struct delayed_work *pDelayedWork
void my_delayed_work_timer_func(unsigned long data);
DECLARE_DELAYED_WORK(dwork, my_delayed_work_timer_func) // compile-time initialization
INIT_DELAYED_WORK(&dwork, my_delayed_work_timer_func) // run-time initialization
INIT_DELAYED_WORK_ONSTACK(&dwork, my_delayed_work_timer_func) // ... same for on-stack dwork object
PREPARE_ DELAYED _WORK(&dwork, new_my_delayed_func) // change the routine in an already initialized struct
/* Deferrable is similar to delayed, but may postpone waking up CPU if sleeping */
DECLARE_DEFERRABLE_WORK(dwork, my_delayed_work_timer_func) // compile-time initialization
INIT_DEFERRABLE_WORK(&dwork, my_delayed_work_timer_func) // run-time initialization
INIT_DEFERRABLE_WORK_ONSTACK(&dwork, my_delayed_work_timer_func) // ... same for on-stack dwork object
PREPARE_ DELAYED _WORK(&dwork, new_my_delayed_func) // change the routine in an already initialized struct
bool queue_delayed_work(wq, struct delayed_work *work, unsigned long delay)
bool schedule_delayed_work(struct delayed_work *work, unsigned long delay)
bool queue_delayed_work_on(int cpu, wq, struct delayed_work *work, unsigned long delay)
bool schedule_delayed_work_on(int cpu, struct delayed_work *work, unsigned long delay)
Similar to queue_work/schedule_work, but additional parameter delay (number of system ticks) specifies minimum time to delay before executing the item. If queue is being drained with drain_queue, (see above).
bool mod_delayed_work(wq, pDelayedWork, unsigned long delay)
bool mod_delayed_work_on(int cpu, wq, pDelayedWork, unsigned long delay)
Modify delay of or queue a delayed work on specific CPU or any CPU.
If pDelayedWork is idle, equivalent to queue_delayed_work_on(); otherwise, modify pDelayedWork 's timer so that it expires after delay. If delay is zero, pDelayedWork is guaranteed to be scheduled immediately regardless of its current state.
Returns FALSE if pDelayedWork was idle and queued, TRUE if pDelayedWork was pending and its timer was modified.
Safe to call from any context including interrupt handler.
bool cancel_work_sync(pWork)
Cancel pWork and wait for its execution to finish.
Can be used even if the work re-queues itself or migrates to another workqueue.
On return, pWork is guaranteed to be not pending or executing on any CPU.
Returns TRUE if pWork was pending, FALSE otherwise.
Caller must ensure that the workqueue on which pWork was last queued can't be destroyed before this function returns.
bool cancel_delayed_work_sync(pDelayedWork)
Cancel a delayed work and wait for it to finish.
Similar to cancel_work_sync(), but for delayed works.
bool cancel_delayed_work(pDelayedWork)
Cancel a pending delayed work.
Returns TRUE if pDelayedWork was pending and canceled, FALSE if wasn't pending.
Work callback function may still be running on return, unless function returns TRUE and the work doesn't re-arm itself. Explicitly flush or use cancel_delayed_work_sync() to wait on it.
Safe to call from any context including IRQ handler.
bool flush_work(pWork)
Wait for a work to finish executing the last queueing instance.
Wait until pWork has finished execution.
pWork is guaranteed to be idle on return if it hasn't been requeued since flush started.
Returns TRUE if flush_work() waited for the work to finish execution, FALSE if it was already idle.
bool flush_delayed_work(pDelayedWork)
Wait for a delayed work to finish executing the last queueing.
Delayed timer is cancelled and the pending work is queued for immediate execution.
Like flush_work(), this function only considers the last queueing instance of pDelayedWork.
Returns TRUE if waited for the work to finish execution, FALSE if it was already idle.
void flush_workqueue(wq)
void flush_scheduled_work(void) // same as flush_workqueue(system_wq)
Ensure that any scheduled work has run to completion.
Forces execution of the workqueue and blocks until its completion.
Sleep until all works which were queued on entry have been handled, but not livelocked by new incoming ones.
This is typically used in driver shutdown handlers.
void drain_workqueue(wq)
Wait until the workqueue becomes empty.
While draining is in progress, only chain queueing is allowed.
In other words, only currently pending or running work items on wq can queue further work items on it.
wq is flushed repeatedly until it becomes empty. The number of flushing is determined by the depth of chaining and should be relatively short.
int schedule_on_each_cpu(work_func_t func)
Execute a function synchronously on each online CPU
Executes func on each online CPU using the system workqueue and blocks until all CPUs have completed.
Very slow.
Returns 0 on success, -errno on failure.
int execute_in_process_context(work_func_t fn, struct execute_work* pExecuteWork)
Execute the routine within user context.
Executes the function immediately if process context is available, otherwise schedules the function for delayed execution.
Returns: 0 if function was executed immediately (i.e. was not in interrupt).
Returns: 1 if was in interrupt and attempted to schedule function for execution.
bool workqueue_congested(unsigned int cpu, wq)
Test whether wq's cpu workqueue for cpu is congested.
There is no synchronization around this function and
the test result is unreliable and only useful as advisory hints or for
debugging.
unsigned int work_cpu(pWork)
Return the last known associated cpu for pWork: CPU number if pWork was ever queued, WORK_CPU_NONE otherwise.
unsigned int work_busy(pWork)
Test whether a work is currently pending or running
There is no synchronization around this function and the test result is unreliable and only useful as advisory hints or for debugging. Especially for reentrant wqs, the pending state might hide the running state.
Returns or'd bitmask of WORK_BUSY_* bits.
Timers (BH):
Called via TIMER_SOFTIRQ .
Timers are not repetitive (once expires, need to be restarted).
void myfunc(unsigned long mydata) { ... }
[static] DEFINE_TIMER(tmr, myfunc, 0, mydata);
struct timer_list tmr;
init_timer(& tmr);
init_timer_onstack(&
tmr); // if variable is on
stack, also call destroy_timer_on_stack(& tmr)
init_timer_deferable(& tmr); // will
not casue CPU to wake up from power sleep
tmr.function = myfunc;
tmr.data = mydata;
tmr.expires = jiffies + HZ / 2;
setup_timer(&tmr, myfunc, mydata)
setup_timer_on_stack(&tmr, myfunc, mydata)
setup_deferable_timer_on_stack(&tmr, myfunc, mydata)
void add_timer(& tmr)
// must not be already pending
void add_timer_on(&tmr, int cpu)
int mod_timer(&tmr,
unsigned long expires)
Equivalent to del_timer(tmr);
tmr.expires = expires; add_timer(tmr);
The only safe way to queue timer when there are multiple unsynchronized
concurrent users of the same timer.
If timer was inactive, returns 0, if was active, returns 1.
int mod_timer_pending(&tmr, unsigned long expires)
Modify an already pending timer.
For active timers the same as mod_timer().
But will not reactivate or modify an inactive timer.
int mod_timer_pinned(&tmr, unsigned long expires)
Update the expire field of an active timer (if the timer is inactive it will be activated) and ensure that the timer is scheduled on the current CPU.
This does not prevent the timer from being migrated when the current CPU goes offline. If this is a problem for
you, use CPU-hotplug notifiers to handle it correctly, for example, cancelling the timer when the corresponding CPU goes
offline.
Equivalent to: del_timer(timer); timer->expires = expires; add_timer(timer);
int timer_pending(&tmr) { return tmr.entry.next != NULL; } // no inherent synchronization
int del_timer(&tmr)
Deactivate timer. OK to call either for active and
inactive timers.
If was inactive, return 0, otherwise (if was active) return 1.
Guarantees that the timer won't be executed in the future, but does not wait
for completion of an already running handler.
int del_timer_sync(&tmr)
Deactivate a timer and wait for the handler to finish.
Synchronization rules: Callers must prevent restarting of the timer, otherwise this function is meaningless.
It must not be called from interrupt contexts unless the timer is an irqsafe one.
The caller must not hold locks which would prevent completion of the timer's handler.
The timer's handler must not call add_timer_on().
For non-irqsafe timers, you must not hold locks that are held in interrupt
context while calling this function. Even if the lock has nothing to do with
the timer in question. Here's why:
CPU0 CPU1
---- ----
<SOFTIRQ>
call_timer_fn();
base->running_timer = mytimer;
spin_lock_irq(somelock);
<IRQ>
spin_lock(somelock);
del_timer_sync(mytimer);
while (base->running_timer == mytimer);
Now del_timer_sync() will never return and never release somelock. The interrupt on the other CPU is waiting to grab somelock but it has interrupted the softirq that CPU0 is waiting to finish.
int try_to_del_timer_sync(&tmr)
Try to deactivate a timer. Upon successful (ret >= 0) exit the timer is not queued and the handler is not running on any CPU.
Hi-res timers:
#include <linux/ktime.h>
#include <linux/hrtimer.h>
/* nanoseconds */
typedef union ktime {
s64 tv64; } ktime_t;
KTIME_SEC_MAX
ktime_t ktime_set(s64 sec, unsigned long ns)
ktime_t timespec_to_ktime(struct timespec ts)
ktime_t timespec64_to_ktime(struct timespec64
ts)
ktime_t timeval_to_ktime(struct timeval tv)
s64 ktime_to_ns(kt)
s64 ktime_to_us(kt)
s64 ktime_to_ms(kt)
struct timespec ktime_to_timespec(kt)
struct timespec ktime_to_timespec64(kt)
struct timeval ktime_to_timeval(kt)
ktime_t ktime_add(kt1, kt2)
ktime_t ktime_sub(kt1, kt2)
ktime_t ktime_add_ns(kt, unsigned long ns)
ktime_t ktime_sub_ns(kt, unsigned long ns)
ktime_t ktime_add_safe(ktime_t kt1, ktime_t kt2)
ktime_t ktime_add_ms(kt, u64 ms)
ktime_t ktime_sub_us(kt, u64 us)
int ktime_compare(kt1, kt2)
bool ktime_equal(kt1, kt2)
bool ktime_after(kt1, kt2)
bool ktime_before(kt1, kt2)
hrtimer_init(timer, CLOCK_MONOTONIC,
HRTIMER_MODE_REL);
timer->function = ftimer;
hrtimer_start(timer, ktime_set(0, ns),
HRTIMER_MODE_REL);
...
hrtimer_cancel(timer); // waits for the handler to finish
static enum hrtimer_restart ftimer(struct
hrtimer *timer)
{
missed
= hrtimer_forward_now(timer, ktime_set(0, ns);
....
return
HRTIMER_NORESTART; // or HRTIMER_RESTART
}
struct hrtimer *timer;
clockid_t which_clock =
CLOCK_MONOTONIC or CLOCK_REALTIME;
enum hrtimer_mode mode =
HRTIMER_MODE_ABS //
absolute
HRTIMER_MODE_REL //
relative to now
HRTIMER_MODE_ABS_PINNED //
absolute + bound to this CPU
HRTIMER_MODE_REL_PINNED // relative + bound to this CPU
void hrtimer_init(timer, which_clock, mode)
void hrtimer_init_on_stack(timer, which_clock,
mode)
void destroy_hrtimer_on_stack(timer)
int hrtimer_start(timer, kt, mode)
int hrtimer_start_range_ns(timer, kt
unsigned long range_ns, mode)
u64 hrtimer_forward(timer, ktime_t now,
ktime_t interval)
u64 hrtimer_forward_now(timer, ktime_t
interval)
ktime_t now =
timer->base->get_time()
ktime_t now =
hrtimer_cb_get_time(timer)
void hrtimer_set_expires(timer, kt)
void hrtimer_set_expires_range(timer, kt,
ktime_t delta) //
delta is extra tolerance
void hrtimer_set_expires_range_ns(timer, kt,
unsigned long delta_ns)
void hrtimer_add_expires(timer, kt)
void hrtimer_add_expires_ns(timer, u64 ns)
ktime_t hrtimer_get_softexpires(timer) //
without added tolerance (i.e. soft)
ktime_t hrtimer_get_expires(timer) //
with tolerance, i.e. soft + delta
ktime_t hrtimer_expires_remaining(timer)
void hrtimer_get_res(which_clock, struct
timespec *tp)
Wait queues:
Replacement for sleep/wake.
Exclusive waiters (those with WQ_FLAG_EXCLUSIVE) count against wakeup limit counter, non-exclusive do not.
wait_queue_head_t wq;
init_waitqueue_head(& wq);
Sample wait cycle:
[static] DEFINE_WAIT(mywait); // create wait queue entry
add_wait_queue(&wq, &mywait); // add it to wait queue
while (! (condition))
{
/* sets current task state */
/* TASK_INTERRUPTIBLE: signal wakes process up */
/* TASK_UNINTERRUPTIBLE: does not */
prepare_to_wait(&wq, &mywait, TASK_INTERRUPTIBLE);
if (signal_pending(current))
... handle signal ...
schedule();
}
finish_wait(&wq, &mywait); // sets task state to TASK_RUNNING and removed mywait off wq
Note: instead of default_wake_function can supply own wake function in mywait.func(mywait.private).
Helper macros:
void wait_event(&wq, condition)
Uninterruptible wait.
void wait_event_lock_irq(&wq, condition, spinlock_t lock)
void wait_event_lock_irq_cmd(&wq, condition, spinlock_t lock, cmd)
Uninterruptible wait.
Condition checked under the lock.
Expected to be called with the lock held, returns with the lock held.
Command cmd is executed right before going to sleep.
int wait_event_interruptible(&wq, condition)
int wait_event_interruptible_lock_irq(&wq, condition, spinlock_t lock)
int
wait_event_interruptible_lock_irq_cmd(&wq,
condition, spinlock_t lock, cmd)
Interruptible wait.
Returns 0 if condition evaluated to true, or -ERESTARTSYS if was interrupted.
Condition checked under the lock.
Expected to be called with the lock held, returns with the lock held.
Command cmd is executed right before going to sleep.
long wait_event_timeout(&wq, condition, timeout) // timeout is in jiffies
Uninterruptible wait with timeout.
Returns 0 if timeout elapsed, otherwise remaining time.
long wait_event_interruptible _timeout(&wq, condition, timeout) // timeout is in jiffies
Interruptible wait with
timeout.
Returns -ERESTARTSYS if sleep was interrupted, 0 if timeout elapsed, otherwise
remaining time.
int wait_event_interruptible_exclusive(&wq, condition)
Interruptible exclusive
wait.
Returns 0 if condition evaluated to true, or -ERESTARTSYS if was interrupted.
void __add_wait_queue_exclusive(&wq, &mywait)
void __add_wait_queue_tail_exclusive(&wq,
&mywait)
void add_wait_queue_exclusive(&wq,
&mywait)
void prepare_to_wait_exclusive(&wq, &mywait, TASK_[UN]INTERRUPTIBLE)
General routines/macros to set up for exclusive wait.
int wait_event_interruptible_exclusive_locked(&wq, condition)
int wait_event_interruptible_exclusive_locked_irq(&wq, condition)
Interruptible wait.
Must be called with wq.lock
held.
Spinlock is unlocked while sleeping but condition testing is done while the
lock
is held and when this macro exits the lock is held.
wait_event_interruptible_exclusive_locked
uses spin_lock()/spin_unlock().
wait_event_interruptible_exclusive_locked_irq
uses spin_lock_irq()/spin_unlock_irq().
Returns -ERESTARTSYS if sleep was interrupted, 0 if condition was satisfied.
int wait_event_killable(&wq, &mywait)
Semi-interruptible (only
by fatal signals) wait with timeout.
Returns 0 if condition evaluated to true, or -ERESTARTSYS if was interrupted.
int
wait_on_bit(void *word, int bit, int (*action)(void *),
unsigned sleepmode)
int wait_on_bit_lock(void *word, int bit, int (*action)(void
*), unsigned sleepmode)
wait_on_bit : wait for a bit to be cleared.
wait_on_bit_lock : wait for a bit to be cleared when wanting to set it.
action is a function used to sleep.
Wake up:
wake_up_all(&wq); // wakes up all waiters
wake_up(&wq);
// wakes up upto one waiter, same as wake_up_nr(&wq, 1)
wake_up_nr(&wq,
5);
// wakes up upto specified number of waiters
Only exclusive waiters (with WQ_FLAG_EXCLUSIVE) count against the counter.
/* same but with queue spinlock held */
unsigned long flags;
spin_lock_irqsave(&q->lock, flags);
wake_up_locked(&wq);
// wakes up upto one waiter
wake_up_all locked(&wq);
// wakes up upto one waiter
spin_unlock_irqrestore(&q->lock, flags);
void wake_up_bit(void* word, int bit)
Wake up waiter on a bit.
Remove from wait queue:
void remove_wait_queue(&wq, &mywait)
Completion variables:
Wait queue plus "done" flag.
struct completion {
unsigned int done;
wait_queue_head_t wait;
};
struct competion comp;
DECLARE_COMPLETION(comp)
DECLARE_COMPLETION_ONSTACK(comp)
#define INIT_COMPLETION(x) ((x).done
=
0)
// reinitialize for reuse
void init_completion(& comp)
void wait_for_completion(&comp)
int wait_for_completion_interruptible(&comp)
int wait_for_completion_killable(&comp)
unsigned long wait_for_completion_timeout(&comp, unsigned long timeout)
long wait_for_completion_interruptible_timeout(&comp, unsigned long timeout)
long wait_for_completion_killable_timeout(&comp, unsigned long timeout)
bool try_wait_for_completion(&comp)
bool completion_done(&comp)
void complete(&comp)
void complete_all(&comp)
Atomic operations on 32-bit counters:
#define ACCESS_ONCE(x) (*(volatile typeof(x) *)&(x)) // note: does not imply memory barrier
typedef struct { volatile int counter; } atomic_t;
atomic_t v = ATOMIC_INIT(77);
int i;
int atomic_read(pv, i) // no implied barriers !
void atomic_set(pv, i) // ...
void atomic_add(i,
pv)
// ...
void atomic_sub(i,
pv)
// ...
void atomic_inc(pv)
// ...
void atomic_dec(pv)
// ...
No implied barriers (compiler or memory) !!
For some operations, use helper functions
void smp_mb__before_atomic_dec()
void smp_mb__after_atomic_dec()
void smp_mb__before_atomic_inc()
void smp_mb__after_atomic_inc()
For others use smp_wmb, smp_rmb, smp_mb or barrier.
int atomic_sub_and_test(i,
pv)
// true if result is zero, performs memory barriers before and after
int atomic_dec_and_test(pv)
// ...
int atomic_inc_and_test(pv)
// ...
int atomic_add_return(i,
pv)
// return result, performs memory barriers before and after
int atomic_sub_return(i,
pv)
// ...
int atomic_inc_return(pv)
// ...
int atomic_dec_return(pv)
// ...
int atomic_add_negative(i, pv) // *pv += i; return true if result is negative, performs memory barriers before and after
int atomic_xchg(pv, i) // returns previous value, performs memory barriers before and after
int atomic_cmpxchg(pv, old, new) // CAS, returns actual old value, performs memory barriers before and after
int atomic_add_unless(pv,
int a, int
mark)
// if (*pv != mark) { *pv += a; return true; } else { return false;
} and does barriers
void atomic_clear_mask(bitmask, pv)
void atomic_set_mask(bitmask, pv)
int _atomic_dec_and_lock(pv , spinlock_t *lock)
Atomically
decrement *pv and if it drops to zero, atomically acquire lock and
return true.
If does not drop to zero, just decrement, do not acquire lock and return false.
Atomic operations on 64-bit counters:
Most 32-bit architectures do not support 64-bit atomic operations, although x86_32 does.
atomic64_t
long
ATOMIT64_INIT(...)
atomic64_read(...)
etc.
Atomic operations on bits:
void set_bit(unsigned long nr, volatile unsigned long *addr) // no barriers implied
void clear_bit(unsigned long nr, volatile unsigned long *addr) // ...
void change_bit(unsigned long nr, volatile unsigned long *addr) // ... (flips the bit)
void smp_mb__before_clear_bit(void)
void smp_mb__after_clear_bit(void)
int test_bit(unsigned long nr, __const__ volatile unsigned long *addr);
int test_and_set_bit(unsigned long nr, volatile unsigned long *addr) // returns boolean, performs memory barriers
int test_and_clear_bit(unsigned long nr, volatile unsigned long *addr)
int test_and_change_bit(unsigned long nr, volatile unsigned long *addr)
int test_and_set_bit_lock(unsigned long nr, unsigned long *addr) // acquire-release semantics
void clear_bit_unlock(unsigned
long nr, unsigned long
*addr)
// ...
Non-atomic operations on bits:
void __set_bit(unsigned long nr, volatile unsigned long *addr)
void __clear_bit(unsigned long nr, volatile unsigned long *addr)
void __change_bit(unsigned long nr, volatile unsigned long *addr)
int __test_and_set_bit(unsigned long nr, volatile unsigned long *addr)
int __test_and_clear_bit(unsigned long nr, volatile unsigned long *addr)
int __test_and_change_bit(unsigned long nr, volatile unsigned long *addr)
void __clear_bit_unlock(unsigned long nr, unsigned long *addr) // implements release barrier
unsigned long find_first_bit(const unsigned long *addr, unsigned long size)
unsigned long find_first_zero_bit(const unsigned long *addr, unsigned long size)
unsigned long find_next_bit(const unsigned long *addr, unsigned long size, unsigned long offset)
if not found, returns value >= size.
int
ffs(int x)
int ffz(int x)
Memory barriers:
rmb, wmb, mb, read_barrier_depends – emit on UP and MP
smp_rmb, smp_wmb, smp_mb, smp_read_barrier_depends – emit MP ; on
UP emit only barrier()
barrier() – compiler barrier
p = ...
read_barrier_depends();
// a weaker form of read barrier, only affecting dependent data
a = *p;
[can drift down]
LOCK barrier
[cannot drift up]
[cannot drift down]
UNLOCK barrier
[can drift up]
Therefore UNLOCK + LOCK = full MB, but LOCK + UNLOCK is not (may drift into the middle and get reverse-ordered there).
smp_mb__before_spinlock() does not let stores before critical section to dirft inside it
set_current_state(TASK_UNINTERRUPTIBLE) does: smp_mb(),
current->state = TASK_UNINTERRUPTIBLE
wake_up does smp_mb
mmiowb() – order writes to IO space (PCI etc.)
Spinlocks:
Not recursive. Disables preemption on local CPU. Optionally disables hardware interrupts or bottom-half processing. While holding a spinlock, must not do anything that will cause sleep. Do not touch pageable (e.g. user) memory, kmalloc(GFP_KERNEL), any semaphore functions or any of the schedule functions, down_interruptible() and down(). Ok to call down_trylock() and up() as they do never sleep. Initialization: spinlock_t lock = SPIN_LOCK_UNLOCKED; // obsolete, incompatible with RT Or: DEFINE_SPINLOCK(name)
Or: void spin_lock_init(&lock);
Disable-restore interrupts on local CPU: unsigned long flags;spin_lock_irqsave(&lock, flags);spin_unlock_irqrestore(&lock, flags); Performs local_irq_save(); preempt_disable(). If knew for sure interrupts were enabled, can do instead: spin_lock_irq(&lock);spin_unlock_irq(&lock); Performs local_irq_disable(); preempt_disable(). If spinlock is never acquired from interrupt handle, can use the form that does not disable interrupts: spin_lock(&lock);spin_unlock(&lock); int spin_trylock(&lock); Performs preempt_disable(). Disable bottom half processing, but do not disable hardware interrupts: spin_lock_bh(&lock);spin_unlock_bh(&lock); int spin_trylock_bh(&lock); Performs local_bh_disable(); preempt_disable(). Nested forms for lockdep: spin_lock_nested(&lock, subclass)spin_lock_irqsave_nested(&lock, flags, subclass) spin_lock_nest_lock(&lock, nest_lock) // signal: ok to take lock despite already holding nest_lock of the same class
RW spinlocks:
Not recursive.Disables preemption on local CPU.Optionally disables hardware interrupts or bottom-half processing. No reader -> writer conversion.Readers are favored over writers and can starve them, in this case plain spinlock_t may be prefereable to rwlock_t. While holding a spinlock, must not do anything that will cause sleep. Do not touch pageable (e.g. user) memory, kmalloc(GFP_KERNEL), any semaphore functions or any of the schedule functions, down_interruptible() and down(). Ok to call down_trylock() and up() as they do never sleep. Initialization: rwlock_t lock = RW_LOCK_UNLOCKED; // obsolete, incompatible with RT Or: DEFINE_RWLOCK(lock)
Or: void rwlock_init(&lock);
Disable-restore interrupts on local CPU: unsigned long flags;read_lock_irqsave(&lock, flags);read_unlock_irqrestore(&lock, flags); write_lock_irqsave(&lock, flags);write_unlock_irqrestore(&lock, flags); Performs local_irq_save(); preempt_disable(). If knew for sure interrupts were enabled, can do instead: read_lock_irq(&lock);read_unlock_irq(&lock); write_lock_irq(&lock);write_unlock_irq(&lock); Performs local_irq_disable(); preempt_disable(). If spinlock is never acquired from interrupt handle, can use the form that does not disable interrupts: read_lock(&lock);read_unlock(&lock); write_lock(&lock);write_unlock(&lock); int read_trylock(&lock);int write_trylock(&lock); Performs preempt_disable(). Disable bottom half processing, but do not disable hardware interrupts: read_lock_bh(&lock);read_unlock_bh(&lock); write_lock_bh(&lock);write_unlock_bh(&lock); Performs local_bh_disable(); preempt_disable().
Local-global spinlock:
· Global data: very fast and scalable read locking, but very slow write locking.
· Per-CPU data: fast write locking on local CPU, possible write locking of other CPU’s data, very slow write locking of all CPUs data.
struct lglock lg;
DEFINE_STATIC_LGLOCK(lg);
void lg_lock_init(&lg, “mylg”);
void lg_local_lock(&lg);
void lg_local_unlock(&lg);
void lg_local_lock_cpu(&lg, int cpu);
void lg_local_unlock_cpu(&lg, int cpu);
void lg_global_lock(&lg);
void lg_global_unlock(&lg);
Mutexes:
Sleepable lock (may sleep when
acquiring, can sleep while holding it).
May not use in softirq or hardirq context.
Non-recursive.
Task may not exit with mutex held.
struct mutex mtx;
[static] DEFINE_MUTEX(mtx);
void mutex_init(&mtx);
void mutex_destroy(&mtx);
void mutex_lock(&mtx)
int mutex_trylock(&mtx)
void mutex_unlock(&mtx) //
must be unlocked by owner only
int mutex_is_locked(&mtx)
int mutex_lock_interruptible(&mtx) // 0 if acquired, otherwise -EINTR
int mutex_lock_killable(&mtx) // …
int atomic_dec_and_mutex_lock(atomic_t* cnt, &mtx)
If decrements cnt to 0, return true holding mutex.
Otherwise return false not holding mutex.
If locking more than one mutex of the same lock validation class, lockdep will complain. To lock multiple mutexes of the same class, designate their subclasses and lock with the following functions.
unsigned int subclass;
void mutex_lock_nested(&mtx, subclass)
void mutex_lock_interruptible_nested(&mtx, subclass)
void mutex_lock_killable_nested(&mtx,
subclass)
void mutex_lock_nest_lock(&mtx,
nest_lock) // signal: ok to take mtx despite already
holding nest_lock of the same class
Mutexes with priority inheritance:
struct rt_mutex rmx;
[static] DEFINE_RT_MUTEX(rmx);
void rt_mutex_init(&rmx)
void rt_mutex_destroy(&rmx)
void rt_mutex_lock(&rmx)
int rt_mutex_trylock(&rmx)
void rt_mutex_unlock(&rmx)
int rt_mutex_is_locked(&rmx)
int rt_mutex_timed_lock(&rmx, struct hrtimer_sleeper *timeout, int detect_deadlock)
success = 0, otherwise –EINTR or –ETIMEOUT or -EDEADLK
int rt_mutex_lock_interruptible(&rmx, int detect_deadlock)
success = 0, otherwise –EINTR or -EDEADLK
Semaphores:
Sleepable lock (may sleep when
acquiring, can sleep while holding it).
May not use in softirq or hardirq context.
struct semaphore sem;
[static] DEFINE_SEMAPHORE(sem);
void sema_init(&sem, int val) // val is maximum number of holders
void down(&sem) // acquire
int down_trylock(&sem) // inverted result: 0 if acquired, 1 if did not
int down_interruptible(&sem) // 0 or -EINTR
int down_killable(&sem) // 0 or -EINTR
int down_timeout(&sem, long jiffies) // 0 or -ETIME
void up(&sem) // release
RW locks (RW semaphores):
Any number of readers, up to 1 writer.
Non-recursive.
Sleepable lock (may sleep when acquiring, can sleep while holding it).
May not use in softirq or hardirq context.
There is no interrptible/killable wait, all wait is uninterruptible.
struct rw_semaphore rws;
[static] DECLARE_SEMAPHORE(rws);
void init_rwsem(&rws)
void down_read(&rws) // acquire
void down_write(&rws)
int down_read_trylock(&rws) // true = ok, false = failure
int down_write_trylock(&rws)
void up_read(&rws) // release
void up_write(&rws)
int rwsem_is_locked(&rws) // true if locked
void downgrade_write(&rws) // downgrade write lock to read lock
If locking more than one RW semaphore of the same lock validation class, lockdep will complain. To lock multiple mutexes of the same class, designate their subclasses and lock with the following functions.
void down_read_nested(&rws, int subclass)
void down_write_nested(&rws, int subclass)
void down_write_nest_lock(&rws, nest_lock) // signal: ok to take rws despite already holding nest_lock of the same class
Seqlocks:
Sequential locks.
· Good when lots of readers, few writers
· Writers take priority over readers
· So readers cannot starve writers
"Write" side (in write_seqlock_xxx)
internally uses spinlock and runs locked code with spinlock held.
"Read" side does not use spinlock.
"Write" side is subject to lock validator, "read" side is
not.
Internally increments a variable inside the lock. When it is odd, write lock is
held.
|
Writer usage |
Reader usage |
|
... write data ... write_sequnlock(&sq) |
start = read_seqbegin(&sq);
... read data ... |
seqlock_t sq;
[static] DEFINE_SEQLOCK(sq);
unsigned int start;
void seqlock_init(& sq)
void write_seqlock(&sq)
int write_tryseqlock(&sq) // true if locked
void write_sequnlock(&sq)
void write_seqlock_irqsave(&sq, flags)
void write_sequnlock_irqrestore(&sq, flags)
void write_seqlock_irq(&sq)
void write_sequnlock_irq(&sq)
void write_seqlock_bh(&sq)
void write_sequnlock_bh(&sq)
void write_seqcount_begin(seqcount_t
*s)
// caller uses his own mutex or other lock, built-in spinlock is not used
void write_seqcount_end(seqcount_t *s) // ...
void write_seqcount_barrier(seqcount_t *s) // invalidate in-progress read operations
start = read_seqbegin(const &sq)
int read_seqretry(const &sq, unsigned start)
start = read_seqbegin_irqsave(&sq, flags)
start = read_seqretry_irqrestore(&sq, iv, flags)
start = __read_seqcount_begin(const seqcount_t *s) // like read_seqbegin, but does not have smp_rmb at the end
start = read_seqcount_begin(const seqcount_t *s) // equivalent to read_seqbegin
start = raw_seqcount_begin(const seqcount_t *s) // get seqcount without waiting for it to go even, plus smp_rmb
int __read_seqcount_retry(const
seqcount_t *s, unsigned start) // like read_seqretry,
but does not issue smp_rmb
//
(caller must issue rmb before the call)
int read_seqcount_retry(const seqcount_t *s, unsigned start) // equivalent to read_seqretry
Lock validator (lockdep):
http://lwn.net/Articles/185666/
Documentation/lockdep-design.txt
Enable CONFIG_DEBUG_LOCK_ALLOC.
Every lock is assigned a class (= “key address”):
· For statically allocated lock it is the address of the lock
· For dynamic locks it is the spot of their init (spin_lock_init, mutex_init etc.) routine
Validator checks for:
· ClassA lock taken after ClassB if previously locks of these two classes were ever taken in inverse order
· ClassX lock is taken when ClassX lock is already held.
o
Exemption: use functions
like mutex_lock_nested and specify subclass.
Validator treats “class+subclass” as a separate class.
·
Locks released in the
order that is not reverse of their acquisition.
(A stack of currently-held locks is maintained, so any lock being released
should be at the top of the stack; anything else means that something strange
is going on.)
· Any (spin)lock ever acquired by hardirq can never be acquired when interrupts (hardirqs) are enabled.
o
Conversely: any lock ever
acquired with hardirqs enabled is “hardirq-unsafe”
and cannot be acquired in hardirq.
· Any (spin)lock ever acquired by softirq can never be acquired when softirqs are enabled.
o Conversely: any lock ever acquired with softirqs enabled is “softirq-unsafe” and cannot be acquired in hardirq.
· Cannot: (holding) hardirq-safe -> (acquire) hardirq-unsafe.
o
Since hardirq-unsafe
-> hardirq-safe is valid, so reverse is invalid, as it would cause lock
inversion.
May be too strong, but it is checked against nevertheless.
· Cannot: (holding) softirq-safe -> (acquire) softirq-unsafe.
Gotchas:
· Unloading of kernel modules causes class ids to be available for reuse and can produce false warning and leakage of class table (that can overflow and result in a message).
· Static initialization of large number of locks (e.g. array of structures with per-entry lock) can cause class table to overflow. Solution: initialize locks dynamically.
Aids:
· /proc/lockdep_stats
· /proc/lockdep
Kernel threads:
struct task_struct* task;
task =
kthread_create(thread_func, void* data, const char namefmt*, ...);
if (! IS_ERR(task)) wake_up_process(task);
Initially SCHED_NORMAL, nice 0.
Can alter with sched_setscheduler[_nocheck](…).
// create thread bound to NUMA memory node
task = kthread_create_on_node(thread_func, void* data, const char namefmt*,
cpu_to_node(cpu), ...);
if (! IS_ERR(task)) wake_up_process(task);
task = kthread_run(thread_func, void* data, const char namefmt*, ...);
int retval = kthread_stop(task);
Returns thread's retval or -EINTR if the process had never started.
int thread_func(void* data)
{
/* check if kthread_stop had been called */
if (kthread_should_stop())
return retval; /* return status to kthread_stop caller */
do_exit();
}
Priority ranges:
task_struct* p;
p->prio
All:
0 (highest) … MAX_PRIO-1 (lowest, 139)
MAX_PRIO = 140
Realtime:
0
(highest) … MAX_RT_PRIO-1 (lowest, 99)
MAX_PRIO = MAX_USER_RT_PRIO = 100
Timeshared:
MAX_RT_PRIO (100) … MAX_PRIO-1 (139)
Default priority for irq threads (PREEMPT_RT):
MAX_USER_RT_PRIO/2 (50)
CPUs:
NR_CPUS – maximum number in the system // eventually will be run-time variable nr_cpu_ids (nr_cpu_ids <= NR_CPUS)
unsigned long my_percpu[NR_CPUS];
int cpu = get_cpu(); // disable preemption and get current processor
my_percpu[cpu]++;
put_cpu(); // enable preemption
int smp_processor_id(); // unsafe if preemption is not disabled
Per-CPU data interface, static form usable only in kernel but not in loadable modules:
DECLARE_PER_CPU(vartype,
varname)
// declare per-CPU variable (not required locally, DEFINE_PER_CPU is ok)
DEFINE_PER_CPU(vartype, varname)
// define and allocate per-CPU variable
DECLARE_PER_CPU_SHARED_ALIGNED(...)
// cacheline aligned
DEFINE_PER_CPU_SHARED_ALIGNED(...)
DECLARE_PER_CPU_ALIGNED(...)
// cacheline aligned
DEFINE_PER_CPU_ ALIGNED(...)
DECLARE_PER_CPU_PAGE_ALIGNED(...)
// page-aligned
DEFINE_PER_CPU_ PAGE_ALIGNED(...)
EXPORT_PER_CPU_SYMBOL(varname)
// export for use by modules
EXPORT_PER_CPU_SYMBOL_GPL(varname)
get_cpu_var(varname)++; // disable preemption, access variable and increment it
put_cpu_var(varname); // reenable preemption
per_cpu(varname, cpu) = 0; // access per-cpu variable instance for particular CPU (does not disable
// preemption and provides by itself no locking)
Per-CPU data interface, dynamic form usable both in kernel and in loadable modules:
void* alloc_percpu(vartype); // on failure returns NULL
void* __alloc_percpu(size_t size, size_t align);
void free_percpu(void* data);
A* p = alloc_percpu(A); // same as below
A* p = alloc_percpu(sizeof(A), __alignof(__A)); // ...
Then can do get_cpu_var(p) and put_cpu_var(p).
this_cpu_read , this_cpu_write, this_cpu_add, this_cpu_sub etc. – operations performed with interrupts or preemption disabled
CPU sets:
typedef struct cpumask { DECLARE_BITMAP(bits, NR_CPUS);
} cpumask_t;
cpumask_t cpumask;
unsigned long* bp = coumask_bits(& cpumask);
const struct cpumask *const cpu_possible_mask; // populatable, e.g. can be hot-plugged, fixed at boot time
const struct cpumask *const cpu_present_mask; // populated
const struct cpumask *const cpu_online_mask; // available to scheduler
const struct cpumask *const cpu_active_mask; // available to migration (a subset of online, currently identical)
#define num_online_cpus() cpumask_weight(cpu_online_mask)
#define num_possible_cpus() cpumask_weight(cpu_possible_mask)
#define num_present_cpus() cpumask_weight(cpu_present_mask)
#define num_active_cpus() cpumask_weight(cpu_active_mask)
#define cpu_online(cpu) cpumask_test_cpu((cpu), cpu_online_mask)
#define cpu_possible(cpu) cpumask_test_cpu((cpu), cpu_possible_mask)
#define
cpu_present(cpu)
cpumask_test_cpu((cpu), cpu_present_mask)
#define
cpu_active(cpu) cpumask_test_cpu((cpu),
cpu_active_mask)
#define
cpu_is_offline(cpu)
unlikely(!cpu_online(cpu))
cpumask_t mask = { CPU_BITS_NONE };
mask_t mask = cpu_none_mask;
mask_t mask = cpu_all_mask;
cpumask_set_cpu(unsigned int cpu, & mask)
cpumask_clear_cpu(unsigned int cpu, & mask)
int cpumask_test_cpu(unsigned int cpu, & mask)
int cpumask_test_and_set_cpu(unsigned int cpu, & mask)
int cpumask_test_and_clear_cpu(unsigned int cpu, & mask)
cpumask_clear(&mask);
cpumask_setall(& mask);
cpumask_and(&mask,
&m1, &m2);
cpumask_or(&mask, &m1, &m2);
cpumask_xor(&mask, &m1, &m2);
cpumask_andnot(&mask, &m1, &m2);
cpumask_complement(&mask, &m1);
bool cpumask_[is]empty(& mask);
bool cpumask_[is]subset(& mask, & superset_mask);
#define cpu_isset(cpu, cpumask) test_bit((cpu), (cpumask).bits)
cpumask_copy(&dst,
&src);
bool cpumask_equal(&m1, &m2)
int cpumask_parse_user(const
char __user *buf, int len,
&mask)
// 0 = ok, otherwise -errno
int cpumask_parselist_user(const char __user *buf, int
len, &mask)
int cpulist_parse(const char *buf, & mask)
int cpumask_scnprintf(char
*buf, int len, &mask)
int cpulist_scnprintf(char *buf, int len,
&mask)
unsigned int cpumask_first(&mask)
// returns >= nr_cpu_ids if none
unsigned int cpumask_next(int n,
&mask)
// returns >= nr_cpu_ids if none
unsigned int cpumask_next_zero(int n,
&mask) // returns >= nr_cpu_ids if none
for_each_cpu(cpu, mask) {...}
// iterate over every cpu in a mask
for_each_cpu_not(cpu, mask)
{...}
// iterate over every cpu not in a mask
for_each_cpu_and(cpu, m1, m2)
{...}
// iterate over every cpu in both masks
#define for_each_possible_cpu(cpu) for_each_cpu((cpu), cpu_possible_mask)
#define for_each_online_cpu(cpu) for_each_cpu((cpu), cpu_online_mask)
#define for_each_present_cpu(cpu) for_each_cpu((cpu), cpu_present_mask)
cpumask_of_node(cpu_to_node(cpu))
Calling function on other CPUs:
void myfunc(void* info);
Handler function is invoked called on remote CPUs in
IPI interrupt context,
on local CPU – with interrupts disabled.
The following functions must be called with interrupts
enabled (or can deadlock).
They return 0 if successful, otherwise –errno (e.g. –ENXIO if CPU is not
online).
If wait is true, waits for completion of the call.
int smp_call_function_single(int
cpuid, myfunc, void *info, int wait);
int smp_call_function_any(&mask,
myfunc, void *info, int wait);
void smp_call_function_many(&mask, myfunc, void *info, bool wait);
Execute myfunc(info) on all CPUs in mask except current CPU.
Preemption must be disabled when calling smp_call_function_many.
May not call it from bottom-half or interrupt handler.
int smp_call_function(myfunc, void *info, int wait);
Call myfunc(info) on all CPUs in cpu_online_mask
except current CPU.
May not call smp_call_function from bottom-half or interrupt
handler.
Temporary disables preemption internally.
int on_each_cpu(myfunc, void *info, int wait);
Call myfunc(info) on all CPUs in cpu_online_mask
and current CPU.
May not call smp_call_function from bottom-half or interrupt
handler.
Temporary disables preemption internally.
void on_each_cpu_mask(&mask, myfunc, void *info, bool
wait);
Call myfunc(info) on all CPUs in the mask including
current CPU if it is in the mask.
May not call smp_call_function from bottom-half or interrupt
handler.
Preemption must be disabled when calling on_each_cpu_mask.
void on_each_cpu_cond(bool (*cond_func)(int cpu, void *info), myfunc, void *info, bool wait, gfp_t gfp_flags);
For each CPU in cpu_online_mask, invoke locally cond_func(cpu, info) and for those CPUs for which it returns true, perform call remotely myfunc(info) and optionally wait. Flags gpf_flags are used to allocate temporary CPU mask block.
May not call on_each_cpu_cond from bottom-half
or interrupt handler.
Temporary disables preemption internally.
Stop Machine:
int stop_machine(int (*fn)(void *), void *data, const struct cpumask *cpus)
Freeze the machine on all CPUs and execute fn(data).
This schedules a thread to be run on each CPU in the cpus mask (or each
online CPU if cpus is NULL) at the highest priority, which threads also
disable interrupts on their respective CPUs. The result is that no one is
holding a spinlock or inside any other preempt-disable region when fn
runs. This is effectively a very heavy lock equivalent to grabbing every
spinlock (and more).
fn(data) is executed only on one CPU, with interrupts disabled.
Memory zones:
|
ZONE_DMA |
pages that can be used for DMA |
x86-32: below 16 MB |
|
ZONE_DMA32 |
pages that can be used for DMA, |
|
|
ZONE_NORMAL |
normal pages, |
on x86-32: 16 MB to 896 MB |
|
ZONE_HIGHMEM |
pages not permanently mapped into kernel memory |
on x86-32: all memory above 896 MB |
|
ZONE_MOVABLE |
(related to hot-plugging) |
|
Normal allocations are usually satisfied from ZONE_NORMAL, but on shortage can
satisfy from ZONE_DMA.
x64 has only ZONE_DMA, ZONE_DMA32 and ZONE_NORMAL.
Memory allocation (kmaloc):
void* kmalloc(size_t
size, gfp_t flags)
kfree(p)
void* kmalloc_array(size_t n, size_t size, gfp_t flags)
void* kcalloc(size_t n, size_t size, gfp_t flags) // zeroes out
void* kzalloc(size_t size, gfp_t flags) // zeroes out
void* kmalloc_node(size_t size, gfp_t flags, int node) // from specific NUMA node
void* kzalloc_node(size_t size, gfp_t flags, int node) // zeroes out
Common flag combinations:
|
GFP_KERNEL |
Default, most usual. |
|
GFP_ATOMIC |
High-priority allocation. Does not
sleep. |
|
GFP_NOWAIT |
Like GFP_ATOMIC, but will not fallback to emergency pool. |
|
GFP_NOIO |
Like GFP_KERNEL, but will not do block
IO. |
|
GFP_NOFS |
Like GFP_KERNEL (can block and initiate
disk IO), but will not do file system IO. |
|
GFP_USER |
Normal allocation, can block. |
|
GFP_HIGHUSER |
Allocate from ZONE_HIGHMEM. Can block. |
|
GFP_HIGHUSER_MOVABLE |
|
|
GFP_TRANSHUGE |
|
|
GFP_DMA |
Allocate from ZONE_DMA. |
|
GFP_DMA32 |
Allocate from ZONE_DMA32 |
Their meanings:
|
GFP_KERNEL |
__GFP_WAIT | __GFP_IO | __GFP_FS |
|
GFP_ATOMIC |
__GFP_HIGH |
|
GFP_NOWAIT |
GFP_ATOMIC & ~__GFP_HIGH |
|
GFP_NOIO |
__GFP_WAIT |
|
GFP_NOFS |
__GFP_WAIT | __GFP_IO |
|
GFP_USER |
__GFP_WAIT | __GFP_IO | __GFP_FS | __GFP_HARDWALL |
|
GFP_HIGHUSER |
_GFP_WAIT | __GFP_IO | __GFP_FS | __GFP_HARDWALL | __GFP_HIGHMEM |
|
GFP_HIGHUSER_MOVABLE |
__GFP_WAIT | __GFP_IO | __GFP_FS | __GFP_HARDWALL | __GFP_HIGHMEM | __GFP_MOVABLE |
|
GFP_TRANSHUGE |
GFP_HIGHUSER_MOVABLE | __GFP_COMP | __GFP_NOMEMALLOC | __GFP_NORETRY | __GFP_NOWARN | __GFP_NO_KSWAPD |
|
GFP_DMA |
__GFP_DMA |
|
GFP_DMA32 |
__GFP_DMA32 |
|
GFP_TEMPORARY |
__GFP_WAIT | __GFP_IO | __GFP_FS | __GFP_RECLAIMABLE |
|
GFP_IOFS |
__GFP_IO | __GFP_FS |
Basic flags:
|
___GFP_DMA |
Allocate from ZONE_DMA |
|
___GFP_DMA32 |
Allocate from ZONE_DMA32 |
|
___GFP_HIGHMEM |
Allocate from ZONE_HIGHMEM |
|
___GFP_MOVABLE |
Allocate from ZONE_MOVABLE |
|
___GFP_WAIT |
Allocator can sleep |
|
___GFP_HIGH |
High-priority: allocator can access emergency pools |
|
___GFP_IO |
Allocator can start block IO |
|
___GFP_FS |
Allocator can start filesystem IO |
|
___GFP_COLD |
Request cold-cache pages instead of trying to return cache-warm pages |
|
___GFP_NOWARN |
Allocator does not print failure warnings |
|
___GFP_REPEAT |
Allocator repeats (once) the allocation if it fails, but the allocation can potentially fail |
|
___GFP_NOFAIL |
Allocator repeats allocation indefinitely, the allocation cannot fail. Deprecated, no new users allowed. |
|
___GFP_NORETRY |
Allocator never retries the allocation if it fails |
|
___GFP_MEMALLOC |
User reserves |
|
___GFP_COMP |
The allocator adds compound page metadata (used internally by hugetlb code) |
|
___GFP_ZERO |
Zero out page content |
|
___GFP_NOMEMALLOC |
Allocator does not fall back on reserves (takes precedence over MEMALLOC if both are specified) |
|
___GFP_HARDWALL |
The allocator enforces "hardwall" cpuset boundaries |
|
___GFP_THISNODE |
Allocate NUMA node-local memory ponly, no fallback |
|
___GFP_RECLAIMABLE |
The allocator marks the pages reclaimable |
|
___GFP_KMEMCG |
Allocation comes from a memcg-accounted resource |
|
___GFP_NOTRACK |
Don't track with kmemcheck |
|
___GFP_NO_KSWAPD |
|
|
___GFP_OTHER_NODE |
On behalf of other node |
|
___GFP_WRITE |
Allocator intends to dirty page |
Memory allocation (slab allocator):
cache (pool) -> set of slab blocks (each is several pages) -> objects in each slab
struct kmem_cache* kmem_cache_create(
"my_struct",
sizeof(my_struct),
size_t
align,
// required alignment,
often L1_CACHE_BYTES, or 0 if SLAB_HWCACHE_ALIGN
unsigned long flags, //
SLAB_xxx, see below
void (*ctor)(void*)) // can be NULL
void kmem_cache_destroy(struct kmem_cache* cache)
|
SLAB_DEBUG_FREE |
DEBUG: perform extensive check on free |
|
SLAB_RED_ZONE |
DEBUG: insert "red zones" around allocated memory to help detect buffer overruns |
|
SLAB_POISON |
DEBUG: fill a slab with known value (0xA5) to catch access to uninitialized memory |
|
SLAB_HWCACHE_ALIGN |
Align objects within a slab to a cache line |
|
SLAB_CACHE_DMA |
Allocate from ZONE_DMA |
|
SLAB_STORE_USER |
DEBUG: store the last owner for bug hunting |
|
SLAB_PANIC |
Panic if allocation fails |
|
SLAB_DESTROY_BY_RCU |
Defer freeing slabs to RCU (read more in header file) |
|
SLAB_MEM_SPREAD |
Spread some memory over cpuset |
|
SLAB_TRACE |
Trace allocations and frees |
|
SLAB_DEBUG_OBJECTS |
|
|
SLAB_NOLEAKTRACE |
Avoid kmemleak tracing |
|
SLAB_NOTRACK |
|
|
SLAB_FAILSLAB |
Fault injection mark |
|
SLAB_RECLAIM_ACCOUNT |
Objects are reclaimable |
|
SLAB_TEMPORARY |
Objects are short-lived |
void* kmem_cache_alloc(cache,
gfp_t flags);
void* kmem_cache_alloc_node(cache, gfp_t flags, int
node)
void kmem_cache_free(cache, void* p);
Memory allocation (virtually contiguous pages):
Allocated pages are virtually
contiguous and not necessarily physically contiguous.
Less performant than kalloc() since need to update page tables and flush
TLBs.
void* vmalloc(unsigned long size);
void* vzalloc(unsigned long size); // zeroed out
void vfree(const void* addr);
void* vmalloc_user(unsigned long size); // memory for user-space, zeroed out
void* vmalloc_node(unsigned long size, int node); // allocate pages in specific NUMA node
void* vzalloc_node(unsigned long size, int node);
void* vmalloc_exec(unsigned long size); // executable memory
void* vmalloc_32(unsigned long size); // 32-bit addressable memory
void* vmalloc_32_user(unsigned long size); // 32-bit addressable memory for user-space, zeroed-out
void* vmap(struct page **pages, unsigned int count, unsigned long flags, pgprot_t prot);
void vunmap(const void* addr); // release mapping
void vmalloc_sync_all(void);
Memory allocation (physical pages):
struct page* alloc_pages(gfp_t flags, unsigned int order)
Allocate (2 ^ order) contiguous
physical pages, return pointer to first pages's page structure.
On failure returns NULL.
unsigned long page_address(struct page* page) // get physical address
unsigned long __get_free_pages(gfp_t
gfp_flags, unsigned int order)
unsigned long __get_free_page(flags)
Same as alloc_pages, but return physical address or 0.
unsigned long get_zeroed_page(gfp_t flags)
Allocate one zeroed page, return physical address or 0.
#define __get_dma_pages(flags, order) __get_free_pages((flags) | GFP_DMA, (order))
void __free_pages(struct
page *page, unsigned int order)
void __free_page(struct page *page)
void free_pages(unsigned
long addr, unsigned int order)
void free_page(unsigned long addr)
void* alloc_pages_exact(size_t
size, gfp_t flags)
void free_pages_exact(void*physaddr, size_t
size)
Allocate contiguous physical pages to hold size bytes, return physical address or NULL on failure.
struct page*
alloc_pages_node(int nid, gfp_t flags, unsigned int order)
struct page* alloc_pages_exact_node(int nid, gfp_t flags,
unsigned int order)
void* alloc_pages_exact_nid(int nid, size_t
size, gfp_t flags)
Mapping physical pages into kernel space:
void* kmap(struct page* page)
If page is in low memory (ZONE_NORMAL, ZONE_DMA) its virtual address is simply returned.
If page is in ZONE_HIGHMEMORY, a mapping is created and
virtual address is returned.
May sleep.
void kunmap(struct page* page)
Unmap mapping created by kmap.
void* kmap_atomic(struct page* page)
void kunmap(struct page* page)
kmap_atomic/kunmap_atomic is significantly faster than kmap/kunmap because no global lock is needed and because the kmap code must perform a global TLB invalidation when the kmap pool wraps.
However when holding an atomic kmap it is not legal to sleep, so atomic kmaps are appropriate for short, tight code paths only.
struct page* kmap_to_page(void * kva)
PFN:
unsigned long pfn = page_to_pfn(page);
if (pfn_valid(pfn))
page = pfn_to_page(pfn);
void get_page(page);
....
void put_page(page);
void *kva = page_address(page)
get
kv-address for a page in lowmem zone
or for a
pages in himem zone mapped into kernel address space
otherwise
returns NULL
if
(virt_addr_valid(kva)) //
for kva in lowmem zone
page
= virt_to_page(kva);
Pin user pages
in memory:
note:
obsolete, should use get_user_pages_locked|unlocked|fast
struct page *pages;
down_read(¤t->mm->mmap_sem);
long nr = get_user_pages(current,
current->mm, (unsigned long) buf, npages, int write, int force, &pages,
NULL);
up_read(¤t->mm->mmap_sem);
.... modify ...
lock_page(page)
set_page_dirty(page)
unlock_page(page)
page_cache_release(page)
Map kernel
memory into userspace (e.g. for mmap):
down_read(¤t->mm->mmap_sem);
err = remap_pfn_range(struct
vm_area_struct *vma, unsigned long addr,
unsigned
long pfn, unsigned long size, pgprot_t prot)
err = remap_pfn_range(vma,
vma->vm_start, vma->vm_pgoff, vma->vm_end - vma->vm_start,
vma->vm_page_prot)
up_read(¤t->mm->mmap_sem);
Map kernel
memory to userspace:
static struct vm_operations_struct xxx_mmap_ops = {
.open = xxx_mm_open,
.close =
xxx_mm_close,
};
static void xxx_mm_open(struct vm_area_struct *vma)
{
struct file
*file = vma->vm_file;
struct
socket *sock = file->private_data;
struct sock
*sk = sock->sk;
if (sk)
atomic_inc(&pkt_sk(sk)->mapped);
}
static void xxx_mm_close(struct vm_area_struct *vma)
{
struct file
*file = vma->vm_file;
struct
socket *sock = file->private_data;
struct sock
*sk = sock->sk;
if (sk)
atomic_dec(&pkt_sk(sk)->mapped);
}
.......
if
(vma->vm_pgoff)
return
-EINVAL;
size
= vma->vm_end - vma->vm_start;
start
= vma->vm_start;
for
(i = 0; i < ....; i++) {
struct
page *page = virt_to_page(po->pg_vec[i]);
int
pg_num;
for
(pg_num = 0; pg_num < ....; pg_num++, page++) {
err
= vm_insert_page(vma, start, page);
if
(unlikely(err))
goto
out;
start
+= PAGE_SIZE;
}
}
vma->vm_ops
= &xxx_mmap_ops;
Memory
leak detection (kmemleak):
http://www.kernel.org/doc/Documentation/kmemleak.txt
Page allocations and ioremap are not tracked.
Only kmalloc, kmem_cache_alloc (slab allocations) and
vmalloc.
Build with
CONFIG_DEBUG_KMEMLEAK
To disable by default:
build with CONFIG_DEBUG_KMEMLEAK_DEFAULT_OFF
boot with kmemleak=on
mount -t
debugfs nodev /sys/kernel/debug
cat /sys/kernel/debug/kmemleak
Clear the list of all current possible memory leaks:
echo clear > /sys/kernel/debug/kmemleak
Trigger an intermediate memory scan:
echo scan > /sys/kernel/debug/kmemleak
cat /sys/kernel/debug/kmemleak
Disable default thread that scans every 10 minutes:
echo 'scan=off' >
/sys/kernel/debug/kmemleak
Dump the information about object at <addr>:
echo 'dump=<addr>' >
/sys/kernel/debug/kmemleak
Also
/proc/slabinfo
Time:
HZ tic ks (jiffies) per second, typically 100 or 1000, also can be NOHZ.
User-visible value is USER_HZ, so when communicating to userland scale like x
/ (HZ / USER_HZ).
Jiffies has unsigned long and 64-bit values (jiffies, jiffies_64).
unsigned long volatile jiffies;
// wraps around if BITS_PER_LONG < 64
u64
jiffies_64;
On x86 they are separate (but jiffies
can overlay lower word of jiffies_64).
On x64 they are the same thing.
jiffies may be read atomically.
jiffies_64 on 32-bit architectures (BITS_PER_LONG < 64) must be read
under seqlock_t jiffies_lock.
Can always use get_jiffies_64(), on 32-bit
architectures it reads data under seqlock, on 64-bit architectures just reads
it.
#define
time_after(a,b)
((long)(b) - (long)(a) < 0))
#define time_before(a,b) time_after(b,a)
#define time_after_eq(a,b) ((long)(a) - (long)(b) >= 0))
#define time_before_eq(a,b) time_after_eq(b,a)
#define time_in_range(a,b,c) (time_after_eq(a,b) && time_before_eq(a,c))
#define time_in_range_open(a,b,c) (time_after_eq(a,b) && time_before(a,c))
#define time_after64(a,b) ((__s64)(b) - (__s64)(a) < 0))
#define time_before64(a,b) time_after64(b,a)
#define time_after_eq64(a,b) ((__s64)(a) - (__s64)(b) >= 0))
#define time_before_eq64(a,b) time_after_eq64(b,a)
#define time_is_before_jiffies(a) time_after(jiffies, a)
#define time_is_after_jiffies(a) time_before(jiffies, a)
#define time_is_before_eq_jiffies(a) time_after_eq(jiffies, a)
#define time_is_after_eq_jiffies(a) time_before_eq(jiffies, a)
unsigned int jiffies_to_msecs(const unsigned long j);
unsigned int jiffies_to_usecs(const unsigned long j);
unsigned long msecs_to_jiffies(const unsigned int m);
unsigned long usecs_to_jiffies(const unsigned int u);
unsigned long timespec_to_jiffies(const struct timespec *value);
void jiffies_to_timespec(const unsigned long jiffies, struct timespec *value);
unsigned long timeval_to_jiffies(const struct timeval *value);
void jiffies_to_timeval(const unsigned long jiffies, struct timeval *value);
clock_t jiffies_to_clock_t(unsigned long x);
clock_t jiffies_delta_to_clock_t(long delta)
unsigned long clock_t_to_jiffies(unsigned long x);
u64 jiffies_64_to_clock_t(u64 x);
u64 nsec_to_clock_t(u64 x);
u64 nsecs_to_jiffies64(u64 n);
unsigned long nsecs_to_jiffies(u64 n);
struct timespec {
__kernel_time_t tv_sec;
long
tv_nsec;
}
Delays:
set_current_state(TASK_[UN]INTERRUPTIBLE)
long remaining = schedule_timeout(10 * HZ)
unsigned long wait_till = jiffies + 5 * HZ;
while (time_before(jiffies, wait_till))
cond_resched();
// invoke scheduler if need_resched is true, e.g. there is some
higher-priority task
void mdelay(unsigned long
msecs)
// busy-wait using calibrated loops
void udelay(unsigned long usecs)
void ndelay(unsigned long nsecs)
const enum hrtimer_mode mode = HRTIMER_MODE_REL;
ktime_t expires;
int schedule_hrtimeout(&expires, mode)
int schedule_hrtimeout_range(&expires,
unsigned long delta, mode)
int schedule_hrtimeout_range_clock(&expires, unsigned long delta, mode, int clock)
On timer tick:
/*
* Event handler for periodic ticks
*/
void tick_handle_periodic(struct clock_event_device *dev)
{
int cpu = smp_processor_id();
ktime_t next;
tick_periodic(cpu);
if (dev->mode != CLOCK_EVT_MODE_ONESHOT)
return;
/*
* Setup the next period for devices, which do not have
* periodic mode:
*/
next = ktime_add(dev->next_event, tick_period);
for (;;) {
if (!clockevents_program_event(dev, next, false))
return;
/*
* Have to be careful here. If we're in oneshot mode,
* before we call tick_periodic() in a loop, we need
* to be sure we're using a real hardware clocksource.
* Otherwise we could get trapped in an infinite
* loop, as the tick_periodic() increments jiffies,
* when then will increment time, posibly causing
* the loop to trigger again and again.
*/
if (timekeeping_valid_for_hres())
tick_periodic(cpu);
next = ktime_add(next, tick_period);
}
}
/*
* Periodic tick
*/
static void tick_periodic(int cpu)
{
if (tick_do_timer_cpu == cpu) {
write_seqlock(&jiffies_lock);
/* Keep track of the next tick event */
tick_next_period = ktime_add(tick_next_period, tick_period);
do_timer(1);
write_sequnlock(&jiffies_lock);
}
update_process_times(user_mode(get_irq_regs()));
profile_tick(CPU_PROFILING);
}
/*
* Must hold jiffies_lock
*/
void do_timer(unsigned long ticks)
{
jiffies_64 += ticks;
update_wall_time();
calc_global_load(ticks);
}
/*
* Called from the timer interrupt handler to charge one tick to the current
* process. user_tick is 1 if the tick is user time, 0 for system.
*/
void update_process_times(int user_tick)
{
struct task_struct *p = current;
int cpu = smp_processor_id();
/* Note: this timer irq context must be accounted for as well. */
account_process_tick(p, user_tick);
run_local_timers();
rcu_check_callbacks(cpu, user_tick);
printk_tick();
#ifdef CONFIG_IRQ_WORK
if (in_irq())
irq_work_run();
#endif
scheduler_tick();
run_posix_cpu_timers(p);
}
/*
* Called by the local, per-CPU timer interrupt on SMP.
*/
void run_local_timers(void)
{
hrtimer_run_queues();
raise_softirq(TIMER_SOFTIRQ);
}
/*
* Account a single tick of cpu time.
* @p: the process that the cpu time gets accounted to
* @user_tick: indicates if the tick is a user or a system tick
*/
void account_process_tick(struct task_struct *p, int user_tick)
{
cputime_t one_jiffy_scaled = cputime_to_scaled(cputime_one_jiffy);
struct rq *rq = this_rq();
if (sched_clock_irqtime) {
irqtime_account_process_tick(p, user_tick, rq);
return;
}
if (steal_account_process_tick())
return;
if (user_tick)
account_user_time(p, cputime_one_jiffy, one_jiffy_scaled);
else if ((p != rq->idle) || (irq_count() != HARDIRQ_OFFSET))
account_system_time(p, HARDIRQ_OFFSET, cputime_one_jiffy,
one_jiffy_scaled);
else
account_idle_time(cputime_one_jiffy);
}
Print messages, dump stack etc.:
printk(KERN_WARNING "format string", args...)
KERN_EMERG
KERN_ALERT
KERN_CRIT
KERN_ERR
KERN_WARNING
KERN_NOTICE
KERN_INFO
KERN_DEBUG
circular buffer, default size 16K (LOG_BUF_LEN),
configurable with CONFIG_LOG_BUF_SHIFT
dump_stack()
__schedule_bug(task)
debug_show_held_locks(task)
print_modules()
print_irqtrace_events(task)
#include <linux/ratelimit.h>
// depreceated since rate-limiting state is global for
all printk_ratelimit() call sites
if (printk_ratelimit())
printk(...)
// better way: limit for a particular call site
printk_ratelimited(KERN_WARNING "format-string", args)
pr_xxx(format, args):
|
pr_emerg |
KERN_EMERG (0) |
|
pr_alert |
KERN_ALERT (1) |
|
pr_crit |
KERN_CRIT (2) |
|
pr_err |
KERN_ERR (3) |
|
pr_warn |
KERN_WARNING (4) |
|
pr_notice |
KERN_NOTICE (5) |
|
pr_info |
KERN_INFO (6) |
|
pr_debug |
KERN_DEBUG(7) |
|
pr_cont |
KERN_CONT = continue line with no NL char |
|
|
KERN_DEFAULT (d) |
to enable all messages: echo 8 >/proc/sys/kernel/printk
default is "warning (4) and up"
content of /proc/sys/kernel/printk (full): <current> <default> <minimum> <boot-time-default>
on boot: loglevel=8
printk_once(...)
printk_emerg_once(...) and other printk_xxx_once(...)
pr_xxx_ratelimited(....)
vprintk(...)
vprintk_emit(...)
hex_dump_to_buffer(...)
print_hex_dump(...)
print_hex_dump_bytes(...)
print_hex_dump_debug(...)
For
drivers:
#include <linux/device.h>
dev_xxx(const struct device *dev, fmt, args)
e.g. dev_dbg(...)
dev_xxx_once(...)
dev_xxx_ratelimited(dev, fmt, args)
dev_vprintk_emit(...)
dev_WARN(...), dev_WARN_ONCE(...)
=> includes file/lineno and backtrace
http://elinux.org/Debugging_by_printing
How to selectively enable/disable pr_debug/dev_dbg call
sites (via debugfs):
https://www.kernel.org/doc/Documentation/dynamic-debug-howto.txt
/proc/sys/kernel/printk_delay
/proc/sys/kernel/printk_ratelimit
/proc/sys/kernel/printk_ratelimit_burst
http://www.ibm.com/developerworks/linux/library/l-kernel-logging-apis/index.html
printk formats: https://www.kernel.org/doc/Documentation/printk-formats.txt
int %d
or %x
unsigned
int %u or %x
long %ld
or %lx
unsigned
long %lu or
%lx
long
long %lld
or %llx
unsigned
long long %llu or %llx
size_t %zu
or %zx
ssize_t %zd
or %zx
s32 %d
or %x
u32 %u
or %x
s64 %lld
or %llx
u64 %llu
or %llx
pointer %p
Also has formats for:
symbolic decoding of pointers (symbol + offset)
physical addresses (phys_addr_t)
DMA addresses (dma_addr_t)
raw buffers as hex string
MAC/FDDI addresses
IPv4/IPv6 addresses
UUID/GUID
dentry names
struct clk
bitmaps
Printing to ftrace buffer:
#include <linux/kernel.h>
trace_printk(...)
trace_puts(str) =>
extra fast
trace_dump_stack()
ftrace_vprintk(...)
Trees:
Read-black tree – self-balancing (semi-balanced) binary search tree:
· each non-leaf node has 1 or 2 children
· value(left child) < value(node) < value(right child)
· depth(deepest path) <= 2 * depth(shallowest path)
struct rb_root {
struct rb_node *rb_node;
};
struct rb_node {
unsigned long __rb_parent_color;
struct rb_node *rb_right;
struct rb_node *rb_left;
};
Typical user node:
struct mytype {
struct rb_node node;
char* mystring;
};
struct rb_root root = RB_ROOT; // { NULL }
#define rb_parent(r) ((struct rb_node *)((r)->__rb_parent_color & ~3))
#define rb_entry(ptr, type, member) container_of(ptr, type, member)
void rb_replace_node(struct rb_node *victim, struct rb_node *new, struct rb_root *root)
void rb_link_node(struct rb_node * node, struct rb_node * parent, struct rb_node ** rb_link)
Searching:
struct mytype *my_search(struct rb_root *root, char *string)
{
struct rb_node *node = root->rb_node;
while (node) {
struct mytype *data = container_of(node, struct mytype, node);
int result;
result = strcmp(string, data->mystring);
if (result < 0)
node = node->rb_left;
else if (result > 0)
node = node->rb_right;
else
return data;
}
return NULL;
}
Remove an existing node:
struct mytype *data = my_search(&mytree, "walrus");
if (data) {
rb_erase(&data->node, &mytree); // void rb_erase(struct rb_node *victim, struct rb_root *tree)
myfree(data);
}
To replace an existing node with the new one with the same key:
void rb_replace_node(struct rb_node *victim, struct
rb_node *new, struct
rb_root *root);
Inserting into tree:
int my_insert(struct rb_root *root, struct mytype *data)
{
struct rb_node **new = &(root->rb_node), *parent = NULL;
/* Figure out where to put new node */
while (*new) {
struct mytype *this = container_of(*new, struct mytype, node);
int result = strcmp(data->mystring, this->mystring);
parent = *new;
if (result < 0)
new = &((*new)->rb_left);
else if (result > 0)
new = &((*new)->rb_right);
else
return FALSE;
}
/* Add new node and rebalance tree. */
rb_link_node(&data->node, parent, new);
rb_insert_color(&data->node, root);
return TRUE;
}
Iterating through the tree:
struct rb_node* rb_first(const struct rb_root*)
struct rb_node* rb_last(const struct rb_root*)
struct rb_node* rb_next(const struct rb_node*)
struct rb_node* rb_prev(const struct rb_node*)
struct rb_node *xnode;
for (xnode = rb_first(&mytree); xnode; xnode = rb_next(xnode))
printk("key=%s\n", rb_entry(xnode, struct mytype, node)->mystring);
Radix tree:
maps "unsigned long" to "void*"
#include
<linux/radix-tree.h>
RADIX_TREE(name, gfp_mask);
struct radix_tree_root my_tree;
INIT_RADIX_TREE(my_tree, gfp_mask);
struct radix_tree_root *tree;
unsigned long key;
void *item;
int radix_tree_insert(tree, key, item);
item = radix_tree_lookup(tree,
key);
item = radix_tree_delete(tree,
key);
Kobjects:
struct kobject {
const char* name;
struct list_head entry;
struct kobject* parent;
struct kset* kset;
struct kobj_type* ktype;
struct sysfs_dirent* sd;
struct kref kref;
unsigned int state_initialized:1;
unsigned int state_in_sysfs:1;
unsigned int state_add_uevent_sent:1;
unsigned int state_remove_uevent_sent:1;
unsigned int uevent_suppress:1;
}
struct kobj_type {
void (*release)(struct kobject *kobj);
const struct sysfs_ops *sysfs_ops;
struct attribute **default_attrs;
const struct kobj_ns_type_operations *(*child_ns_type)(struct kobject *kobj);
const void *(*namespace)(struct kobject *kobj);
}
struct kobject* kobject_get(struct kobject *kobj)
If kobj is not NULL, increment reference counter and return kobj.
void kobject_put(struct kobject *kobj)
If kobj is not NULL, decrement reference
counter, if goes to zero then release the object.
kobject/kset sample: LINUX_ROOT/samples/kobject
kobj_map:
Handles device numbers.
There are two kobj_maps: one for block devices and one for character
devices.
Each struct probe describes device number range starting at dev
with length range.
struct kobj_map * kobj_map_init(kobj_probe_t
*base_probe, struct subsystem *s)
int kobj_map(struct kobj_map *domain,
dev_t dev, unsigned long range,
struct module *owner, kobj_probe_t *get, int (*lock)(dev_t, void *), void *data)
void kobj_unmap(struct kobj_map *domain, dev_t dev, unsigned long range)
struct kobject * kobj_lookup(struct kobj_map *domain, dev_t dev, int *index)
Finds the given device number dev on the given map domain. If the owner field is set, we temporarily take a reference on the corresponding module via try_module_get(owner) in order to protect the lock and get calls. If the lock function is present it will be called, and the present probe skipped if it returns an error. Then the get function is called to get the kobject for the given device number. The resulting kobject is returned as value, and the offset in the interval of device numbers is returned via index; module is released via module_put.
Lockup
detection:
/proc/sys/kernel/nmi_watchdog
/proc/sys/kernel/watchdog_thresh
Default is 10 seconds,
meaning 10 seconds for hard lockup detection and 20 seconds for soft lockup
detection.
Hard lockup is
lock up in kernel mode with interrupts disabled.
Soft lockup is
lock up in kernel mode not letting other tasks to run.
Code is in
kernel/watchdog.c
Docs in
Documentation/lockup-watchdogs.txt
Using floating point in kernel:
#include <asm/i387.h>
kernel_fpu_begin();
.....
kernel_fpu_end();
RCU:
For read-mostly data, when transient reader/writer
inconsistency ok.
Decreases read-side overhead, increases write-side overhead.
#include <linux/rcupdate.h>
// read-side RCU critical section:
// - cannot
sleep, but can be preemted if CONFIG_PREEMPT_RCU
// - can be
nested
static struct xxx_struct* __rcu xptr;
rcu_read_lock();
p = rcu_dereference(xptr);
// p is valid here
do_something_with(p);
rcu_read_unlock();
// p is invalid here
// update section (synchronous, waiting for RCU sync)
// use spinlocks, semaphores etc. to interlock updaters
// cannot be called from irq or bh context
spin_lock(&updater_lock);
p = xptr;
rcu_assign_pointer(xptr, new_p);
spin_unlock(&updater_lock);
synchronize_rcu(); //
wait for grace period
kfree(p);
// update section (asynchronous,non-waiting for RCU
sync)
// use spinlocks, semaphores etc. to interlock updaters
spin_lock(&updater_lock);
p = xptr;
rcu_assign_pointer(xptr, new_p);
spin_unlock(&updater_lock);
call_rcu(&p->x_rcu, xxx_rcu_func);
struct xxx_struct {
struct rcu_head x_rcu;
};
void xxx_rcu_func(struct rcu_head *p_rcu_head)
{
struct
my_struct *p = container_of(p_rcu_head, struct my_struct, x_rcu);
destroy_my_struct(p);
}
Note: RCU callbacks
can be invoked in softirq context. Therefore it cannot block, and any lock
acquired within RCU callback must be
acquired elsewhere with spin_lock_irq or spin_lock_bh,
to avoid self-deadlock. Watch out for locks indirectly acquired
by API functions (e.g. kfree etc.) called by the
callback!
Any lock acquired by RCU callback must be acquired elsewhere
with softirq disabled (e.g. spin_lock_bh,
spin_lock_irqsave), or self-deadlock
will result.
RCU callbacks are usually executed on the same CPU, as
scheduled by call_rcu_xxx, but this
is not guaranteed (for example, if CPU goes offline, pending callbacks will be
transferred to another CPU for execution).
RCU read-side primitives do not necessarily contain memory barriers. Therefore CPU and compiler may reorder code
into and out of RCU
read-side critical sections. It is the responsibility of the RCU
update-side primitives to deal with this.
What is RCU, Fundamentally? http://lwn.net/Articles/262464
What is RCU? Part 2: Usage http://lwn.net/Articles/263130
RCU part 3: the RCU API http://lwn.net/Articles/264090
The RCU API, 2010 Edition http://lwn.net/Articles/418853
"Is parallel programming hard..."
http://www.kernel.org/pub/linux/kernel/people/paulmck/perfbook/perfbook.html
http://www.rdrop.com/users/paulmck/RCU
http://www.kernel.org/doc/Documentation/RCU/whatisRCU.txt
http://www.kernel.org/doc/Documentation/RCU/UP.txt
http://www.kernel.org/doc/Documentation/RCU/listRCU.txt
http://www.kernel.org/doc/Documentation/RCU/trace.txt
|
enumerate list entries |
|
|
read_lock(&xxx_lock); list_for_each_entry(p,
&xxx_listhead, list) { ... } read_unlock(&xxx_lock); |
rcu_read_lock(); list_for_each_entry_rcu(p,
&xxx_listhead, list) { ... } rcu_read_unlock(); |
|
add list entry |
|
|
write_lock(&xxx_lock); if (p->condition) list_add(&p->list, xxx_listhead); else list_add_tail(&p->list,
xxx_listhead); write_unlock(&xxx_lock); |
lock(&xxx_lock); if (p->condition) list_add_rcu(&p->list, xxx_listhead); else list_add_tail_rcu(&p->list,
xxx_listhead); unlock(&xxx_lock); |
|
delete list entry |
|
|
write_lock(&xxx_lock); list_for_each_entry(p,
&xxx_listhead, list) { if (p->condition) { list_del(&e->list); write_unlock(&xxx_lock); return; } } write_unlock(&xxx_lock); |
lock(&xxx_lock); list_for_each_entry_rcu(p,
&xxx_listhead, list) { if (p->condition) { list_del_rcu(&p->list); unlock(&xxx_lock); call_rcu(&p->rcu,
xxx_free); return; } } unlock(&xxx_lock); |
|
in-place updates |
|
|
write_lock(&xxx_lock); list_for_each_entry(p,
&xxx_listhead, list) { if (p->condition) { p->a = new_a; p->b = new_b; write_unlock(&xxx_lock); return; } } write_unlock(&xxx_lock); |
lock(&xxx_lock); list_for_each_entry_rcu(p,
&xxx_listhead, list) { if (p->condition) { np = copy(p); if (np ==
NULL) ... np->a = new_a; np->b = new_b; list_replace_rcu(&p->list,
&np->list); unlock(&xxx_lock); call_rcu(&p->rcu,
xxx_free); return; } } unlock(&xxx_lock); |
|
eliminating stale data |
|
|
If stale data cannot be
tolerated, use per-entry “deleted” flag and per-entry spinlock, and re-verify
the validity of data. |
|
https://www.kernel.org/doc/Documentation/RCU/checklist.txt
https://www.kernel.org/doc/Documentation/RCU/NMI-RCU.txt
https://www.kernel.org/doc/Documentation/RCU/arrayRCU.txt
https://www.kernel.org/doc/Documentation/RCU/rcu_dereference.txt
https://www.kernel.org/doc/Documentation/RCU/rcubarrier.txt
https://www.kernel.org/doc/Documentation/RCU/lockdep.txt
https://www.kernel.org/doc/Documentation/RCU/lockdep-splat.txt
|
Attribute |
RCU Classic |
RCU BH |
RCU Sched |
Realtime RCU |
SRCU |
QRCU |
|
Purpose |
Wait
for RCU read-side critical sections |
Wait
for RCU-BH read-side critical sections & irqs |
Wait
for RCU-Sched read-side critical sections, preempt-disable regions, hardirqs
& NMIs |
Realtime
response |
Wait
for SRCU read-side critical sections, allow sleeping readers |
Sleeping
readers and fast grace periods |
|
Read-side
primitives |
rcu_read_lock() |
rcu_read_lock_bh() |
preempt_disable() |
rcu_read_lock() |
srcu_read_lock() |
qrcu_read_lock() |
|
Update-side
primitives |
synchronize_rcu() |
synchronize_rcu_bh() |
synchronize_sched() |
synchronize_rcu() |
synchronize_srcu() |
synchronize_qrcu() |
|
Update-side
primitives |
synchronize_rcu_expedited() |
synchronize_rcu_bh_expedited() |
synchronize_rcu_sched_expedited() |
|
synchronize_srcu_ expedited() |
|
|
Update-side
primitives |
call_rcu() |
call_rcu_bh() |
call_rcu_sched() |
call_rcu() |
N/A |
N/A |
|
Update-side
primitives |
rcu_barrier() |
rcu_barrier_bh() |
rcu_barrier_sched() |
rcu_barrier() |
N/A |
N/A |
|
Read
side constraints |
No
blocking except preemption ans spinlock acquisition |
No
bh enabling |
No
blocking |
No
blocking except preemption and lock acquisition |
No
synchronize_srcu() |
No
synchronize_qrcu() |
|
Read
side overhead |
Preempt
disable/enable (free on non-PREEMPT) |
BH
disable/enable |
Preempt
disable/enable (free on non-PREEMPT) |
Simple
instructions, irq disable/enable |
Simple
instructions, preempt disable/enable |
Atomic
increment and decrement of shared variable |
|
Asynchronous
update-side overhead (for example, call_rcu()) |
sub-microsecond |
sub-microsecond |
sub-microsecond |
sub-microsecond |
N/A |
N/A |
|
Grace-period
latency |
10s
of milliseconds |
10s
of milliseconds |
10s
of milliseconds |
10s
of milliseconds |
10s
of milliseconds |
10s
of nanoseconds in absence of readers |
|
Non-PREEMPT_RT
implementation |
RCU
Classic |
RCU
BH |
RCU
Classic |
N/A |
SRCU |
N/A |
|
PREEMPT_RT
implementation |
N/A |
Realtime
RCU |
Forced
Schedule on all CPUs |
Realtime
RCU |
SRCU |
N/A |
|
RCU |
Critical sections |
Grace period |
Barrier |
|
Classic |
rcu_read_lock |
synchronize_net |
rcu_barrier |
|
BH |
rcu_read_lock_bh |
call_rcu_bh |
rcu_barrier_bh |
|
Sched |
rcu_read_lock_sched rcu_read_lock_sched_notrace rcu_read_unlock_sched_notrace |
synchronize_sched call_rcu_sched synchronize_sched_expedited |
rcu_barrier_sched |
|
SRCU |
srcu_read_lock srcu_read_unlock srcu_dereference srcu_dereference_check srcu_read_lock_held |
synchronize_srcu |
srcu_barrier |
SRCU initialization/cleanup:
init_srcu_struct
cleanup_srcu_struct
|
updater uses |
readers must use |
|
synchronize_rcu call_rcu |
rcu_read_lock |
|
synchronize_rcu_bh call_rcu_bh |
rcu_read_lock_bh An exception: may also rcu_read_lock() and rcu_read_unlock() instead of rcu_read_lock_bh() and rcu_read_unlock_bh() if local bottom
halves are already known to be disabled, for example, in irq or softirq
context. |
|
synchronize_sched call_rcu_sched |
disable preemption,
possibly by calling rcu_read_lock_sched |
|
synchronize_srcu |
srcu_read_lock srcu_read_unlock (with the same with the same srcu_struct) |
·
RCU list traversal
and pointer dereference primitives (list_xxx_rcu,
rcu_dereference_xxx) must be used:
o
inside RCU
read-side critical section
o
or protected by
update-side lock.
·
synchronize_rcu
will only wait for all currently executing rcu_read_lock
sections. It does not (necessarily) wait for irqs, NMIs, preempt_disable
sections, or idle loops to complete.
·
synchronize_irq(irq) waits for pending IRQ handlers on other CPUs
·
synchronize_sched waits for pending preempt_disable code sequences, including NMI and
non-threaded hardware-interrupt handlers.
However, this does not guarantee that softirq handlers will have
completed, since in some kernels, these handlers can run in process context,
and can block.
|
Category |
Primitives |
Purpose |
|
List
traversal |
list_for_each_entry_rcu() |
Iterate
over an RCU-protected list from the beginning. |
|
list_for_each_entry_continue_rcu() |
Iterate
over an RCU-protected list from the specified element. |
|
|
list_entry_rcu() |
Given
a pointer to a raw list_head in an RCU-protected
list, return a pointer to the enclosing element. |
|
|
list_first_entry_rcu() |
Return
the first element of an RCU-protected list. |
|
|
List
update |
list_add_rcu() |
Add
an element to the head of an RCU-protected list. |
|
list_add_tail_rcu() |
Add
an element to the tail of an RCU-protected list. |
|
|
list_del_rcu() |
Delete
the specified element from an RCU-protected list, poisoning the ->pprev pointer but not the ->next pointer. |
|
|
list_replace_rcu() |
Replace
the specified element in an RCU-protected list with the specified element. |
|
|
list_splice_init_rcu() |
Move
all elements from an RCU-protected list to another RCU-protected list. |
|
|
Hlist
traversal |
hlist_for_each_entry_rcu() |
Iterate
over an RCU-protected hlist from the beginning. |
|
hlist_for_each_entry_rcu_bh() |
Iterate
over an RCU-bh-protected hlist from the beginning. |
|
|
hlist_for_each_entry_continue_rcu() |
Iterate
over an RCU-protected hlist from the specified element. |
|
|
hlist_for_each_entry_continue_rcu_bh() |
Iterate
over an RCU-bh-protected hlist from the specified element. |
|
|
Hlist
update |
hlist_add_after_rcu() |
Add
an element after the specified element in an RCU-protected hlist. |
|
hlist_add_before_rcu() |
Add
an element before the specified element in an RCU-protected hlist. |
|
|
hlist_add_head_rcu() |
Add
an element at the head of an RCU-protected hlist. |
|
|
hlist_del_rcu() |
Delete
the specified element from an RCU-protected hlist, poisoning the ->pprev pointer but not the ->next pointer. |
|
|
hlist_del_init_rcu() |
Delete
the specified element from an RCU-protected hlist, initializing the element's
reverse pointer after deletion. |
|
|
hlist_replace_rcu() |
Replace
the specified element in an RCU-protected hlist with the specified element. |
|
|
Hlist
nulls traversal |
hlist_nulls_for_each_entry_rcu() |
Iterate
over an RCU-protected hlist-nulls list from the beginning. |
|
Hlist
nulls update |
hlist_nulls_del_init_rcu() |
Delete
the specified element from an RCU-protected hlist-nulls list, initializing
the element after deletion. |
|
hlist_nulls_del_rcu() |
Delete
the specified element from an RCU-protected hlist-nulls list, poisoning the ->pprev pointer but not the ->next pointer. |
|
|
hlist_nulls_add_head_rcu() |
Add
an element to the head of an RCU-protected hlist-nulls list. |
|
Category |
Primitives |
Purpose |
|
Pointer
update |
rcu_assign_pointer() |
Assign
to an RCU-protected pointer. |
|
Pointer
access |
rcu_dereference() |
Fetch
an RCU-protected pointer, giving an lockdep-RCU error message if not in an
RCU read-side critical section. |
|
rcu_dereference_bh() |
Fetch
an RCU-protected pointer, giving an lockdep-RCU error message if not in an RCU-bh
read-side critical section. |
|
|
rcu_dereference_sched() |
Fetch
an RCU-protected pointer, giving an lockdep-RCU error message if not in an
RCU-sched read-side critical section. |
|
|
srcu_dereference() |
Fetch
an RCU-protected pointer, giving an lockdep-RCU error message if not in the
specified SRCU read-side critical section. |
|
|
rcu_dereference_protected() |
Fetch
an RCU-protected pointer with no protection against concurrent updates, giving
an lockdep-RCU error message if the specified lockdep condition does not
hold. This primitive is normally used when the update-side lock is held. |
|
|
rcu_dereference_check() |
Fetch
an RCU-protected pointer, giving an lockdep-RCU error message if (1) the
specified lockdep condition does not hold and (2) not under the protection of
rcu_read_lock(). |
|
|
rcu_dereference_bh_check() |
Fetch
an RCU-bh-protected pointer, giving an lockdep-RCU error message if (1) the specified
lockdep condition does not hold and (2) not under the protection of rcu_read_lock_bh() (2.6.37 or later). |
|
|
rcu_dereference_sched_check() |
Fetch
an RCU-sched-protected pointer, giving an lockdep-RCU error message if (1) the
specified lockdep condition does not hold and (2) not under the protection of
rcu_read_lock_sched() or friend
(2.6.37 or later). |
|
|
srcu_dereference_check() |
Fetch
an SRCU-protected pointer, giving an lockdep-RCU error message if (1) the
specified lockdep condition does not hold and (2) not under the protection of
the specified srcu_read_lock() (2.6.37 or
later). |
|
|
rcu_dereference_index_check() |
Fetch
an RCU-protected integral index, giving an lockdep-RCU error message if the
specified lockdep condition does not hold. |
|
|
rcu_access_pointer() |
Fetch
an RCU-protected value (pointer or index), but with no protection against
concurrent updates. This primitive is normally used to do pointer
comparisons, for example, to check for a NULL pointer. |
|
|
rcu_dereference_raw() |
Fetch
an RCU-protected pointer with no lockdep-RCU checks. Use of this primitive is
strongly discouraged. If you must use this primitive, add a comment stating
why, just as you would with smp_mb(). |
Free an object:
void kfree_rcu (ptr, rcu_head) //
Helper function.
Initializers:
RCU_INIT_POINTER(ptr, NULL);
If
you are creating an RCU-protected linked structure that is accessed by a single
external-to-structure RCU-protected pointer, then you may use RCU_INIT_POINTER
to initialize the internal RCU-protected pointers, but you must use rcu_assign_pointer
to initialize the external-to-structure pointer -after- you have completely
initialized the reader-accessible portions of the linked structure.
struct x x = {
.group_leader = &tsk, \
RCU_POINTER_INITIALIZER(real_cred,
&init_cred), \
RCU_POINTER_INITIALIZER(cred,
&init_cred), \
.comm =
INIT_TASK_COMM, \
}
Unloading a
module:
void rcu_barrier() //
call from module unload, waits for callbacks to complete
void rcu_barrier_bh()
void rcu_barrier_sched()
This primitive does not
necessarily wait for an RCU grace period to complete. For example, if there are
no RCU callback queued anywhere in the system , then rcu_barrier is within its rights to return immediately, without
waiting for anything, much less an RCU grace period.
If a callback can re-post itself,
module unload function should empoy a global flag to disable the reposting before
calling rcu_barrier().
Debugging:
CONFIG_PROVE_RCU: check that accesses to RCU-protected data structures
are carried out under the proper RCU read-side critical section, while holding
the right combination of locks, or whatever other conditions are appropriate.
CONFIG_DEBUG_OBJECTS_RCU_HEAD: check that you don't pass the same object to
call_rcu() (or friends) before an RCU grace period has elapsed since the last
time that you passed that same object to call_rcu() (or friends).
__rcu sparse checks: tag the pointer to the RCU-protected
data structure with __rcu, and sparse will warn you if you access that pointer
without the services of one of the variants of rcu_dereference().
RCU-BH has faster grace period than
classic RCU (and is helpful e.g. in case of DDoS-attacks cases).
void
call_rcu_bh (struct rcu_head * head, void (*func)
(struct rcu_head *head))
call_rcu_bh assumes that the read-side critical
sections end on completion of a softirq handler. This means that read-side
critical sections in process context must not be interrupted by softirqs. This
interface is to be used when most of the read-side critical sections are in
softirq context. RCU read-side critical sections are delimited by : - rcu_read_lock and rcu_read_unlock, if in interrupt context. OR - rcu_read_lock_bh and rcu_read_unlock_bh,
if in process context. These may be nested.
void rcu_read_lock_bh ()
An equivalent of rcu_read_lock, but to be used when updates are being done using call_rcu_bh or synchronize_rcu_bh.
Since both call_rcu_bh and synchronize_rcu_bh
consider completion of a softirq handler to be a quiescent state, a process in
RCU read-side critical section must be protected by disabling softirqs.
Read-side critical sections in interrupt context can use just rcu_read_lock, though this should at
least be commented to avoid confusing people reading the code.
Note that rcu_read_lock_bh and the matching rcu_read_unlock_bh must occur in the same context, for example, it
is illegal to invoke rcu_read_unlock_bh
from one task if the matching rcu_read_lock_bh
was invoked from some other task.
RCU-SCHED:
void call_rcu_sched (struct rcu_head
* head, void (*func) (struct rcu_head *rcu))
call_rcu_sched assumes that the read-side critical sections end on enabling of
preemption or on voluntary preemption. RCU read-side critical sections are
delimited by : - rcu_read_lock_sched and rcu_read_unlock_sched,
OR anything that disables preemption. These may be nested.
void rcu_read_lock_sched ( void)
An equivalent of rcu_read_lock, but to be used when updates are being done using call_rcu_sched or synchronize_rcu_sched. Read-side critical sections can also be
introduced by anything that disables preemption, including local_irq_disable and friends.
Note that rcu_read_lock_sched and the matching rcu_read_unlock_sched must occur in the same context, for example,
it is illegal to invoke rcu_read_unlock_sched
from process context if the matching rcu_read_lock_sched
was invoked from an NMI handler.
void synchronize_sched()
Wait until an rcu-sched grace period has elapsed.
Control will return to the caller some time after a
full rcu-sched grace period has elapsed, in other words after all currently
executing rcu-sched read-side critical sections have completed. These read-side critical sections are
delimited by rcu_read_lock_sched()
and rcu_read_unlock_sched(), and may
be nested. Note that preempt_disable(), local_irq_disable(), and so on may be used in place of rcu_read_lock_sched().
This means that all preempt_disable
code sequences, including NMI and non-threaded hardware-interrupt handlers, in
progress on entry will have completed before this primitive returns. However, this does not guarantee that softirq
handlers will have completed, since in some kernels, these handlers can run in
process context, and can block.
Note that this guarantee implies further
memory-ordering guarantees. On systems with more than one CPU, when synchronize_sched() returns, each CPU is
guaranteed to have executed a full memory barrier since the end of its last
RCU-sched read-side critical section whose beginning preceded the call to synchronize_sched(). In addition, each CPU having an RCU read-side
critical section that extends beyond the return from synchronize_sched() is guaranteed to have executed a full memory
barrier after the beginning of synchronize_sched()
and before the beginning of that RCU read-side critical section. Note that these guarantees include CPUs that
are offline, idle, or executing in user mode, as well as CPUs that are
executing in the kernel.
Furthermore, if CPU A invoked synchronize_sched(), which returned to its caller on CPU B, then
both CPU A and CPU B are guaranteed to have executed a full memory barrier
during the execution of synchronize_sched()
-- even if CPU A and CPU B are the same CPU (but again only if the system has
more than one CPU).
This primitive provides the guarantees made by the (now
removed) synchronize_kernel()
API. In contrast, synchronize_rcu() only guarantees that rcu_read_lock() sections will have completed. In "classic
RCU", these two guarantees happen to be one and the same, but can differ
in realtime RCU implementations.
RCU Misc:
void call_rcu_tasks (struct rcu_head *
head, void (*func) (struct rcu_head *head))
call_rcu_tasks assumes that the read-side critical
sections end at a voluntary context switch (not a preemption!), entry into
idle, or transition to usermode execution. As such, there are no read-side
primitives analogous to rcu_read_lock and rcu_read_unlock because
this primitive is intended to determine that all tasks have passed through a
safe state, not so much for data-strcuture synchronization.
synchronize_rcu_expedited()
synchronize_sched_expedited()
Complete faster, but more expensive.
Cannot be called from a CPU-hotplug notifier or while holding a lock that is
acquired by CPU-hotplug notifier.
SRCU:
srcu_xxx may only be invoked from a process context.
However can enter read-side critical section in a
hardirq or exception handler with srcu_read_lock_raw,
then exit it in the task that was interrupted with srcu_read_unlock_raw.
SRCU overhead is amortized only over those updates sharing a given srcu_struct, rather than being globally amortized as they are for other forms of RCU. Therefore, SRCU should be used in preference to rw_semaphore only in extremely read-intensive situations, or in situations requiring SRCU's read-side deadlock immunity or low read-side realtime latency.
PREEMPT_RT patch
CONFIG_PREEMPT_NONE server
CONFIG_PREEMPT_VOLUNTARY
desktop (preemption in select points only)
CONFIG_PREEMPT low-latency
desktop (preemption anywhere except spinlocks and “no preempt” sections)
CONFIG_PREEMPT_RT_BASE
CONFIG_PREEMPT_RT_FULL
In (RT || CONFIG_IRQ_FORCED_THREADING && boot
param threadirqs), interrupts are threaded, unless IRQF_NO_THREAD is set in struct irqaction.flags.
Flag IRQF_NO_SOFTIRQ_CALL disables softirq processing when exiting primary
handler – the handler must not request BH/softirq processing.
|
local_irq_disable() |
On some architectures, do not actually
disable interrupts in RT kernel.
To actually disable interrupts, use raw_local_xxx() version. |
|
spinlock_t |
In RT kernel, implemented via rt_mutex. |
|
seqlock_t |
In RT kernel, critical sections are preemptible. Priority inheritance on write side. Read side is non-blocking, so no heavy priority inversion issue here. |
|
struct semaphore |
In RT kernel, implements priority
inheritance. |
|
struct rw_semaphore |
In RT kernel, subject to priority
inheritance, and only one task can hold reader lock, but that task can
acquire read lock recursively. |
|
DEFINE_PER_CPU_LOCKED(type,
name)
get_per_cpu_locked(var,
cpu) |
Associate spinlock_t with per-cpu
variable.
Get variable without acquiring the lock, either because it was already acquired, or because making RCU read-side reference to the variable, so do not need a lock. |
See more:
http://lwn.net/Articles/146861/?format=printable
In RT mode:
o spinlocks (spinlock_t and rwlock_t) are preemptible, see <linux/spinlock_rt.h>
o RCU read-side critical sections (rcu_read_lock()) are preemptible
o therefore cannot acquire spinlock with preemption or interrupts disabled (trylock is ok)
o spinlock_irq_save(spinlock_t) does not disable interrupts
o to disable preemption and/or interrupts use spin_lock(raw_spinlock_t) and spinlock_irq_save(raw_spinlock_t)
o avoid the use of raw_spinlock_t unless really necessary
o preemption can be disabled via preempt_disable(), get_cpu_var() or disabling interrupts
o since spinlocks can now sleep, be careful when accessing current->state and other scheduling state data
Lazy preempt was introduced to mitigate execution of SCHED_OTHER tasks on RT kernel:
RT sucks throughput wise for ordinary SCHED_OTHER tasks. One major issue is the wakeup of tasks which are right away preempting the waking task while the waking task holds a lock on which the woken task will block right after having preempted the wakee. In mainline this is prevented due to the implicit preemption disable of spin/rw_lock held regions. On RT this is not possible due to the fully preemptible nature of sleeping spinlocks.
Though for a SCHED_OTHER task preempting another SCHED_OTHER task this is really not a correctness issue. RT folks are concerned about SCHED_FIFO/RR tasks preemption and not about the purely fairness driven SCHED_OTHER preemption latencies.
So I introduced a lazy preemption mechanism which only applies to SCHED_OTHER tasks preempting another SCHED_OTHER task. Aside of the existing preempt_count each tasks sports now a preempt_lazy_count which is manipulated on lock acquiry and release. This is slightly
incorrect as for lazyness reasons I coupled this on migrate_disable/enable so some other mechanisms get the same treatment (e.g. get_cpu_light).
Now on the scheduler side instead of setting NEED_RESCHED this sets NEED_RESCHED_LAZY in case of a SCHED_OTHER/SCHED_OTHER preemption and therefor allows to exit the waking task the lock held region before the woken task preempts. That also works better for cross CPU wakeups as the other side can stay in the adaptive spinning loop.
For RT class preemption there is no change. This simply sets NEED_RESCHED and forgoes the lazy preemption counter.
migrate_disable(…)
if RT_FULL SMP, migrate_disable =
preempt_lazy_disable(); // lazy-disable preemption (if CONFIG_PREEMPT_LAZY, and for SCHED_OTHER/SCHED_OTHER only)
… // disable current CPU hot-removal (pin_current_cpu)
p->migrate_disable = 1; // disable task migration to another CPU
if RT_FULL UP, migrate_disable = noop (just barrier)
in all other cases migrate_disable = preempt_disable
spin_lock(lock)
migrate_disable();
// disable task migration to another CPU (or if not RT_FULL, simply preempt_disable)
rt_spin_lock(lock);
// acquire underlying rt_mutex, can sleep
spin_lock_bh(lock)
local_bh_disable(); // disable BH processing
migrate_disable();
// disable task migration to another CPU (or if not RT_FULL, simply preempt_disable)
rt_spin_lock(lock);
// acquire underlying rt_mutex, can sleep
Sequential
files:
struct file
(readonly, sequential access) -> seq_file -> provider
seq_file serves
as an adapter between consumer and producer.
Reading is driven by the consumer (i.e. struct
file* object).
seq_file translates read requests into the calls to producer walking
the structure.
File read
operations pull in data from the provider.
Every file
"read" operation starts by consuming the existing the buffer first.
By default,
buffer size is one page.
Once the buffer
is empty, "read" then fills in the buffer by calling a producer.
Approximate
sequence on every buffer fill-in:
start
next - show
...
next - show
stop
#ifdef
CONFIG_PROC_FS
static const
struct file_operations xxx_file_operations = {
.open =
xxx_open,
.read =
seq_read,
.llseek =
seq_lseek,
.release = seq_release
};
static int
xxx_open(struct inode *inode, struct file *file)
{
return
seq_open(file, &xxx_op);
}
static const struct
seq_operations xxx_op = {
.start = xxx_start,
.next = xxx_next,
.stop = xxx_stop,
.show = xxx_show
};
static void
*xxx_start(struct seq_file *m, loff_t *pos)
{
// lock the
structure
// use pos as
input and forward to *pos
// may save context
in m->private for use by next/show/stop
// return
"next/show.arg" or NULL
}
static void
*xxx_next(struct seq_file *m, void *arg, loff_t *pos)
{
// ++*pos;
// return
"next/show.arg" or NULL
}
static void
xxx_stop(struct seq_file *m, void *arg)
{
// unlock the
structure
}
static int
xxx_show(struct seq_file *m, void *arg)
{
seq_printf(m,
"0x%p", ...);
seq_puts(m,
"abc");
seq_putc(m,
'\n');
}
One-item (simplified) case on top of seq_file:
static const
struct file_operations xxx_fops = {
.open = xxx_open,
.read = seq_read,
.llseek = seq_lseek,
.release = single_release,
};
static int
xxx_open(struct inode *inode, struct file *file)
{
return
single_open(file, xxx_show, NULL);
}
static int
xxx_show(struct seq_file *m, void *v)
{
seq_printf(m,
"0x%p", ...);
seq_puts(m,
"abc");
seq_putc(m,
'\n');
return 0;
}
Procfs:
#include <linux/proc_fs.h>
struct proc_dir_entry *pde;
pde = proc_create_data("pde", S_IRWXU, NULL,
&xxx_file_operations, NULL);
mde = proc_mkdir("dir", NULL);
spde = proc_create_data("spde1", S_IRWXU,
spde, &xxx_file_operations, NULL);
...
remove_proc_entry(spde);
remove_proc_entry(mde);
remove_proc_entry(pde);
Kprobes:
#include <linux/kprobes.h>
struct kprobe kp = {
// .addr = do_fork,
//
.symbol_name =
"do_fork",
.pre_handler = pre_handler,
.post_handler = post_handler
};
ret = register_kprobe(&kp);
if (ret < 0) {
...
return ret;
}
....
unregister_kprobe(&kp);
static int __kprobes pre_handler(struct kprobe *p,
struct pt_regs *regs)
{
...
return 0;
}
static void __kprobes post_handler(struct kprobe *p,
struct pt_regs *regs, unsigned long flags)
{
...
}
kprobes sample:
LINUX_ROOT/samples/kprobes
Jprobes:
struct jprobe jp = {
.entry =
jp_handler_func,
};
jp.kp.addr = (kprobe_opcode_t *)func;
ret = register_jprobe(&jp);
if (ret < 0) {
...
return ret;
}
...
unregister_jprobe(&jp);
static void __kprobes jp_handler_func(long r0, long r1)
{
if (r0 ==
FUNC_ARG1 && r1 == FUNC_ARG2)
...
jprobe_return();
}
Return
probes:
static int __kprobes
kretprobe_handler(struct kretprobe_instance *ri, struct
pt_regs *regs)
{
if
(regs_return_value(regs) == ...)
...
return 0;
}
struct kretprobe
rp = {
.handler = kretprobe_handler,
};
rp.kp.addr = (kprobe_opcode_t *)func;
ret = register_kretprobe(&rp);
if (ret < 0) {
...
return ret;
}
...
unregister_kretprobe(&rp);
Hardware breakpoints to intercerpt data access/code execution:
sample: LINUX_ROOT/samples/hw_breakpoint
register_wide_hw_breakpoint(...), unregister_wide_hw_breakpoint(...)
Notifiers:
struct atomic_notifier_head {
spinlock_t
lock;
struct
notifier_block __rcu *head;
};
struct blocking_notifier_head {
struct
rw_semaphore rwsem;
struct
notifier_block __rcu *head;
};
struct notifier_block {
notifier_fn_t
notifier_call;
struct
notifier_block __rcu *next;
int
priority;
};
ATOMIC_NOTIFIER_HEAD(h);
BLOCKING_NOTIFIER_HEAD(h);
ATOMIC_INIT_NOTIFIER_HEAD(h);
BLOCKING_INIT_NOTIFIER_HEAD(h);
int atomic_notifier_chain_register(nh, nb);
int atomic_notifier_chain_unregister(nh, nb);
int atomic_notifier_call_chain(nh, unsigned long val,
void *v);
int blocking_notifier_chain_register(nh, nb);
int blocking_notifier_chain_unregister(nh, nb);
int blocking_notifier_call_chain(nh, unsigned long val,
void *v);
int notifier_fn(struct notifier_block *nb, unsigned
long action, void *data)
{
// return
NOTIFY_OK
// return
NOTIFY_STOP
}
SRCU notifiers are using sleepable RCUs instead of
rwsem.
debugfs:
#include <linux/debugfs.h>
#if defined(CONFIG_DEBUG_FS)
static struct dentry *dir = 0;
static u32 hello = 0;
dir = debugfs_create_dir(“test", NULL);
if (!dir) ...
junk = debugfs_create_u32("hello", 0666, dir,
&hello);
if (!junk) ...
...
debugfs_remove_recursive(dir);
==================================
static int xxx_write_op(void *data, u64 value)
{
sum +=
value;
return 0;
}
DEFINE_SIMPLE_ATTRIBUTE(xxx_fops, NULL, xxx_write_op,
"%llu\n");
dir = debugfs_create_dir("test", NULL);
if (!dir) ...
junk = debugfs_create_file( "xxx", 0666, dir,
NULL, &xxx_fops);
if (!junk) ...
....
debugfs_remove_recursive(dir);
debugfs_create_u8(name, mode, parent, u8 *value);
debugfs_create_u16(name, mode, parent, u16 *value);
debugfs_create_u32(name, mode, parent, u32 *value);
debugfs_create_u64(name, mode, parent, u64 *value);
debugfs_create_x8(name, mode, parent, u8 *value);
debugfs_create_x16(name, mode, parent, u16 *value);
debugfs_create_x32(name, mode, parent, u32 *value);
debugfs_create_x64(name, mode, parent, u64 *value);
debugfs_create_size_t(name, mode, parent, size_t *value);
debugfs_create_atomic_t(name, mode, parent, atomic_t *value);
debugfs_create_bool(name, mode, parent, u32 *value);
debugfs_create_blob(name, mode, parent, struct debugfs_blob_wrapper *blob);
debugfs_create_regset32(name, mode, parent, struct debugfs_regset32 *regset)
void debugfs_print_regs32(struct seq_file *s, const struct debugfs_reg32 *regs, int
nregs, void __iomem *base, char *prefix);
debugfs_create_u32_array(name, mode, parent, u32 *array, u32 elements);
debugfs_create_devm_seqfile(struct device *dev, const char *name, parent,
int (*read_fn)(struct seq_file *s, void
*data));
Userspace/kernel
communications:
·
standard file
systems: procfs, sysfs, debugfs, sysctl, configfs
·
custom device
·
custom file system
·
kernel socket,
netlink socket
·
kfifo
LINUX_ROOT/samples/kfifo
LINUX_ROOT/include/linux/kfifo.h
·
mmap + other
shared memory (map user page to kernel space or vice versa)
·
futex, signal
·
syscall
http://www.ibm.com/developerworks/linux/library/l-tasklets/index.html
http://www.linuxjournal.com/article/5833
http://web.archive.org/web/20051023100157/http://kernelnewbies.org/documents/kdoc/kernel-locking/lklockingguide.html
http://www.crashcourse.ca/wiki/index.php/Kernel_topics
http://www.crashcourse.ca/wiki/index.php/Linux_kernel
https://www.kernel.org/doc/htmldocs/kernel-api
http://www.ibm.com/developerworks/linux/library/l-task-killable
http://www.makelinux.net/ldd3 ch 5
https://www.kernel.org/pub/linux/kernel/people/rusty/kernel-locking/c214.html
### kthreads, waiting for completion,
priorities
### lists 85-96
### signal processing by thread (especially kill and stop)